در این مطلب، ویدئو پایتون از یک فایل متنی می خواند و کلمات را با فرکانس با استفاده از فهرست و فرهنگ لغت برمی گرداند با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:08:13
تصاویر این ویدئو:



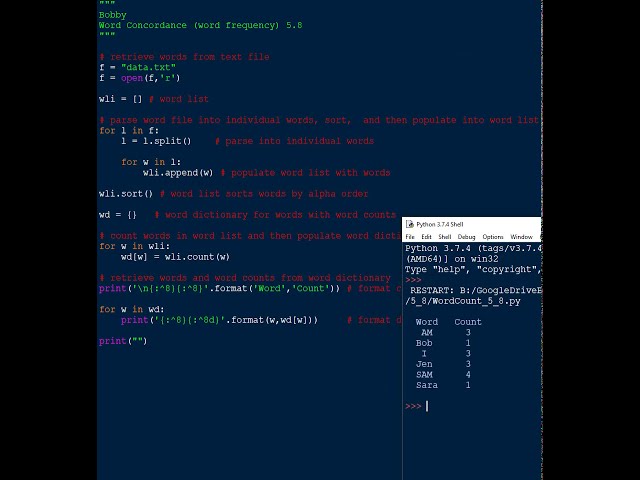
قسمتی از زیرنویس این فیلم:
00:00:00,030 –> 00:00:04,400
امروز می خواهم در مورد یک تکلیف
2
00:00:04,400 –> 00:00:06,930
پنج نقطه هشت صحبت کنم که مربوط به
3
00:00:06,930 –> 00:00:10,340
تطابق کلمات است و معنی آن این است
4
00:00:10,340 –> 00:00:13,139
که ما به یک فایل متنی نگاه می کنیم
5
00:00:13,139 –> 00:00:15,839
و کلمات را از یک فایل متنی بیرون می
6
00:00:15,839 –> 00:00:19,350
آوریم و ما میخواهیم تعداد کلماتی را
7
00:00:19,350 –> 00:00:22,500
که وجود دارد به اندازه
8
00:00:22,500 –> 00:00:25,170
کلمات منحصربهفرد آنها بشماریم، بنابراین فکر میکنم
9
00:00:25,170 –> 00:00:27,119
نمونهای از Sam I am Sam I am وجود دارد
10
00:00:27,119 –> 00:00:28,650
و بنابراین ما تعداد Sam را میشماریم،
11
00:00:28,650 –> 00:00:30,119
تعداد چشمها و تعداد
12
00:00:30,119 –> 00:00:34,170
دستها. خیلی خب، پس بیایید اینجا را ببینیم
13
00:00:34,170 –> 00:00:38,300
اولین کاری که باید انجام دهیم این است که یک
14
00:00:38,300 –> 00:00:40,530
فایل متنی داشته باشیم که این داده ها را داشته باشد، بنابراین من
15
00:00:40,530 –> 00:00:41,820
می روم و به یکی نگاهی می اندازم
16
00:00:41,820 –> 00:00:44,550
و یکی درست می کنم، بنابراین برای اینکه این فایل کار کند، می
17
00:00:44,550 –> 00:00:46,980
خواهید فایل متنی شما در
18
00:00:46,980 –> 00:00:51,390
همان دایرکتوری با فایل dot py خود باشید، بنابراین
19
00:00:51,390 –> 00:00:53,760
من کلمه خود را مطابقت میکنم و
20
00:00:53,760 –> 00:00:56,910
فایل دادهام این است که من سام هستم،
21
00:00:56,910 –> 00:01:01,320
سام هستم، سام هستم و باب سارا جن
22
00:01:01,320 –> 00:01:03,300
جن جن را دارم و همه آنها در یک
23
00:01:03,300 –> 00:01:07,650
فهرست هستند. خوب پس بیایید این را حذف کنیم
24
00:01:07,650 –> 00:01:10,979
و من داده های فایل متنی خود را صدا می زنم، منظورم این است که شما
25
00:01:10,979 –> 00:01:17,310
می توانید نام آن را هر چه می خواهید بگذارید، پس طبق
26
00:01:17,310 –> 00:01:20,790
معمول ما به w
27
00:01:20,790 –> 00:01:25,259
ما می خواهیم هدر خود را اینجا قرار دهیم، بنابراین
28
00:01:25,259 –> 00:01:28,100
من این کار را سریع انجام می دهم
29
00:01:44,270 –> 00:01:46,320
و اولین کاری که می خواهیم
30
00:01:46,320 –> 00:01:47,820
انجام دهیم این است که می خواهیم
31
00:01:47,820 –> 00:01:52,710
کدی را که قرار است انجام دهیم بنویسیم. برای بیرون آوردن داده ها
32
00:01:52,710 –> 00:01:54,509
از فایل، بنابراین من می خواهم آن را سریع انجام دهم،
33
00:01:54,509 –> 00:02:14,810
بنابراین کاری که من در اینجا انجام دادم این
34
00:02:14,810 –> 00:02:18,900
است که بازیابی کلمات را از فایل های متنی در
35
00:02:18,900 –> 00:02:20,640
یک نظر قرار می دهم و فقط می خواهم
36
00:02:20,640 –> 00:02:23,390
مال خود را a fit مخفف فایل صدا کنم.
37
00:02:23,390 –> 00:02:28,590
داده های برابر با نقطه txt و F برابر است با باز کردن F و سپس
38
00:02:28,590 –> 00:02:30,569
خواندن و این R مخفف read است، بنابراین ما می
39
00:02:30,569 –> 00:02:32,790
خواهیم فایل متنی داده های فایل را باز کنیم
40
00:02:32,790 –> 00:02:37,709
و آن را به خوبی بخوانیم، بنابراین
41
00:02:37,709 –> 00:02:40,140
ما فایل خود را باز می کنیم تا چیزی که باید
42
00:02:40,140 –> 00:02:43,650
آماده کنم. بنابراین باید لیستی تهیه کنم که در آن
43
00:02:43,650 –> 00:02:47,390
داده ها را جمع
44
00:03:02,310 –> 00:03:07,540
آوری کنم، البته متاسفم که امروز صبح زیاد قهوه خوردم و
45
00:03:07,540 –> 00:03:09,120
46
00:03:09,120 –> 00:03:14,770
فکر نمی کنم خوب باشد، بنابراین این
47
00:03:14,770 –> 00:03:16,240
لیست ما برای جمع آوری داده ها
48
00:03:16,240 –> 00:03:19,150
و چیز بعدی است که می خواهیم برای انجام این کار،
49
00:03:19,150 –> 00:03:22,930
میخواهیم دادههای خود را تجزیه کنیم و
50
00:03:22,930 –> 00:03:26,260
از یک حلقه for استفاده
51
00:03:26,260 –> 00:03:27,670
میکنیم و از طریق لیست تکرار
52
00:03:27,670 –> 00:03:30,430
میکنیم و میخواهیم تقسیم کنیم. هر خط را به
53
00:03:30,430 –> 00:03:32,760
کلمات تقسیم می کنم و من آن کلمات هر کلمه را تقسیم می کنم و
54
00:03:32,760 –> 00:03:35,470
55
00:03:35,470 –> 00:03:39,220
هر کلمه را در لیست وارد می کنیم تا
56
00:03:39,220 –> 00:03:40,450
کدی بنویسم و سپس آن
57
00:03:40,450 –> 00:03:43,090
ا به درستی توضیح خواهم داد. did
58
00:03:43,090 –> 00:03:46,810
here در اولین حلقه for است که ما می خواهیم
59
00:03:46,810 –> 00:03:48,940
از طریق هر خط کد موجود در
60
00:03:48,940 –> 00:03:52,000
فایل تکرار کنیم و آنها را به
61
00:03:52,000 –> 00:03:53,140
کلمات جداگانه تقسیم می کنیم و به همین دلیل است که من
62
00:03:53,140 –> 00:03:54,850
این موارد را اینجا نظر
63
00:03:54,850 –> 00:03:57,340
دادم سپس یک کد دیگر را برای حلقه
64
00:03:57,340 –> 00:03:58,930
و در حلقه دوم for ما در
65
00:03:58,930 –> 00:04:01,120
هر خط تکرار می کنیم و
66
00:04:01,120 –> 00:04:02,860
از طریق هر کلمه می گذریم، ببخشید و
67
00:04:02,860 –> 00:04:07,810
هر کلمه را
68
00:04:07,810 –> 00:04:10,330
در لیست قرار می دهیم، خوب ادامه دهید تا آن را
69
00:04:10,330 –> 00:04:12,489
آرایه بنامید، اما همیشه همینطور است بنابراین این همان کاری است که
70
00:04:12,489 –> 00:04:14,470
این دو در اینجا انجام می دهند، تجزیه
71
00:04:14,470 –> 00:04:15,880
کلمات جداگانه و سپس پر کردن کلمات
72
00:04:15,880 –> 00:04:22,720
در لیست بسیار خوب است، بنابراین من این خط بعدی را
73
00:04:22,720 –> 00:04:25,360
اینجا نوشتم و اینجا بسیار ساده است،
74
00:04:25,360 –> 00:04:27,130
تمام کاری که ما انجام می دهیم این است که
75
00:04:27,130 –> 00:04:29,710
لیست را بر اساس آلفا مرتب می کنیم. نام لیست
76
00:04:29,710 –> 00:04:33,010
مرتبسازی نقطهای، مرتبسازی تابع را فراخوانی میکند
77
00:04:33,010 –> 00:04:36,729
و آن را در خط بعدی مرتب میکند کد
78
00:04:36,729 –> 00:04:38,950
اینجا همان چیزی است که من کلمه
79
00:04:38,950 –> 00:04:41,380
دیکشنری می نامم، بنابراین من آن را
80
00:04:41,380 –> 00:04



![فیلم آموزشی: هری مولد - پایتون [ ویدیوی رسمی ]](http://s1.program98.com/learn/wp-content/uploads/upyt/6MHvg5WTA3cimage2.jpg)