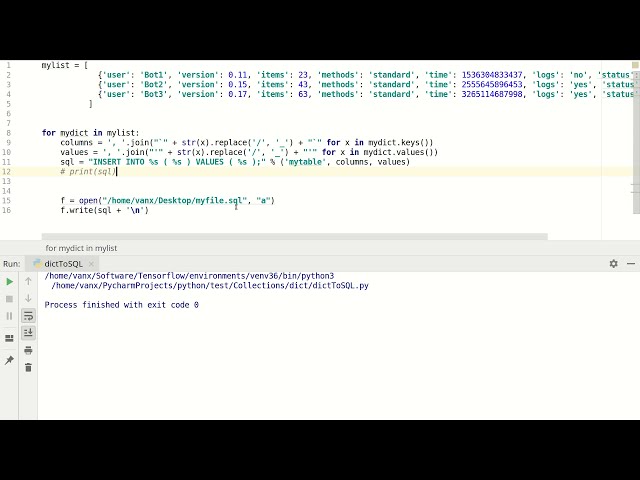
در این مطلب، ویدئو برنامه نویسی موازی بیوانفورماتیک – آموزش (شمارش Kmer در پایتون) – HPC با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:40:00
تصاویر این ویدئو:



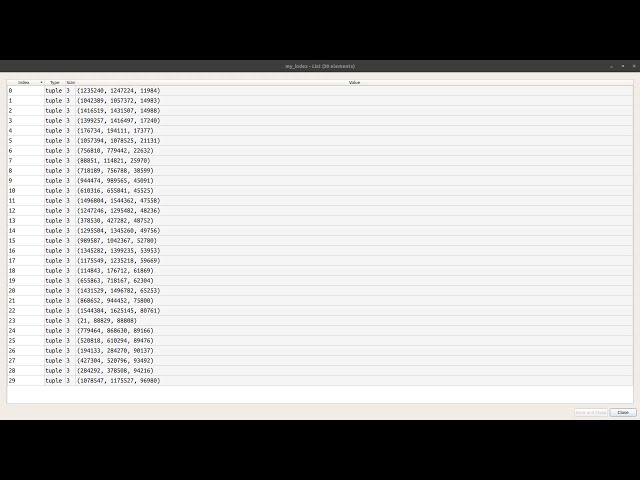
قسمتی از زیرنویس این فیلم:
00:00:00,120 –> 00:00:08,280
[موسیقی]
2
00:00:08,690 –> 00:00:11,910
سلام به همه در این ویدیو میخواهم
3
00:00:11,910 –> 00:00:13,969
شما را با نحوهی معرفی آسان
4
00:00:13,969 –> 00:00:16,350
فلج به کد بیوانفورماتیک خود
5
00:00:16,350 –> 00:00:19,050
با استفاده از کتابخانه زنده شغلی در
6
00:00:19,050 –> 00:00:22,080
پایتون آشنا
7
00:00:22,080 –> 00:00:24,199
8
00:00:24,199 –> 00:00:28,320
کنم. فایل FASTA و فقط در صورتی
9
00:00:28,320 –> 00:00:29,880
که با یک یا چند مورد از این
10
00:00:29,880 –> 00:00:32,969
مفاهیم تازه کار هستید، من به طور خلاصه توضیح خواهم داد،
11
00:00:32,969 –> 00:00:33,780
بنابراین k-mer چیست،
12
00:00:33,780 –> 00:00:36,450
k-mer به سادگی اصطلاحی است که ما برای
13
00:00:36,450 –> 00:00:39,239
توصیف یک قطعه کوچک از دنبالهای از
14
00:00:39,239 –> 00:00:42,870
DNA یک آینه 5 استفاده میکنیم. دنباله ای از
15
00:00:42,870 –> 00:00:45,770
پنج نوکلئوتید خواهد بود، یک آینه شش می تواند دنباله ای
16
00:00:45,770 –> 00:00:49,200
از شش نوکلئوتید باشد و یک
17
00:00:49,200 –> 00:00:51,120
آینه یازده یک دنباله نرم
18
00:00:51,120 –> 00:00:55,860
از یازده نوکلئوتید خواهد بود و به همین ترتیب،
19
00:00:55,860 –> 00:00:58,500
واقعاً همه چیز است، پس
20
00:00:58,500 –> 00:01:00,780
حالا اگر با کدگذاری آشنا نیستید، موازی سازی چیست.
21
00:01:00,780 –> 00:01:03,090
به طور موازی و
22
00:01:03,090 –> 00:01:05,159
یادگیری ماشینی زیادی با استفاده از GPU انجام
23
00:01:05,159 –> 00:01:07,350
نداده اید، به احتمال زیاد اکثریت قریب به اتفاق
24
00:01:07,350 –> 00:01:08,939
تمام کدهایی که نوشته اید
25
00:01:08,939 –> 00:01:11,220
به صورت متوالی اجرا شده باشد، همانطور که
26
00:01:11,220 –> 00:01:13,770
در اینجا در سمت چپ ترسیم شده است، تصور
27
00:01:13,770 –> 00:01:17,759
کنید CPU های خود را دارید و e هشت هسته و
28
00:01:17,759 –> 00:01:19,619
شما باید محاسبات خود را از یک تا ده
29
00:01:19,619 –> 00:01:22,799
وارد کنید تا اجرا شود و سپس این
30
00:01:22,799 –> 00:01:25,049
فقط یک هسته است که تمام حجم کاری را انجام می دهد،
31
00:01:25,049 –> 00:01:27,509
ممکن است احساس کنید کد شما در حال حاضر سریع است،
32
00:01:27,509 –> 00:01:30,240
اما وقتی وارد تجزیه و تحلیل
33
00:01:30,240 –> 00:01:32,970
فایل های داده های بزرگ مانند DNA می شوید، اجرای
34
00:01:32,970 –> 00:01:36,000
ترتیبی است. دیگر کارآمد نیست،
35
00:01:36,000 –> 00:01:37,890
بنابراین میتوانید تصور کنید که استفاده از چندین
36
00:01:37,890 –> 00:01:39,900
هسته زمان اجرای
37
00:01:39,900 –> 00:01:42,600
شما را به شدت افزایش میدهد، همانطور که در
38
00:01:42,600 –> 00:01:44,640
سمت راست میبینید، میتوانید برای
39
00:01:44,640 –> 00:01:47,610
مثال از چهار تای آنها استفاده کنید، در این مورد هسته
40
00:01:47,610 –> 00:01:50,130
اول محاسبه یک پنج
41
00:01:50,130 –> 00:01:52,619
و نه دو را میگیرد. گرفتن دو شش و ده
42
00:01:52,619 –> 00:01:56,250
و غیره که گفته می
43
00:01:56,250 –> 00:01:59,219
شود در واقع هر کار به راحتی قابل موازی سازی نیست، اما
44
00:01:59,219 –> 00:02:01,159
مواردی که ما اغلب به عنوان
45
00:02:01,159 –> 00:02:04,310
موازی شرم آور از آنها یاد می کنیم،
46
00:02:04,619 –> 00:02:07,450
خوشبختانه در یک فایل سریعتر
47
00:02:07,450 –> 00:02:09,580
با ورودی های متعدد تکرار می شوند و سپس
48
00:02:09,580 –> 00:02:12,730
شمارش دوربین ها چنین مثالی
49
00:02:12,730 –> 00:02:15,880
است. یک فایل سریعتر یک فایل سریعتر به سادگی
50
00:02:15,880 –> 00:02:18,220
یک فایل متنی برای نمایش توالی DNA یا
51
00:02:18,220 –> 00:02:20,860
پروتئین است و پسوندهای عمومی فایل
52
00:02:20,860 –> 00:02:25,209
شامل نقطه FASTA نقطه F a SF
53
00:02:25,209 –> 00:02:30,430
a است. dot seq و dot FSA و هر ورودی
54
00:02:30,430 –> 00:02:32,440
داخل فایل FASTA با یک هدر شروع می
55
00:02:32,440 –> 00:02:35,530
شود که با علامت بزرگتر
56
00:02:35,530 –> 00:02:37,510
نشان داده می شود و یک برچسب که به شما کمک می کند
57
00:02:37,510 –> 00:02:40,510
دنباله خاصی را شناسایی کنید، بنابراین در
58
00:02:40,510 –> 00:02:42,940
اینجا یک ورودی و اینجا یک ورودی دیگر
59
00:02:42,940 –> 00:02:46,299
از همان فایل FASTA است. سپس آنچه
60
00:02:46,299 –> 00:02:48,489
برای هر ورودی در ادامه می آید
61
00:02:48,489 –> 00:02:50,530
نوکلئوتیدها یا آمینو اسیدهایی هستند که
62
00:02:50,530 –> 00:02:53,650
دنباله را تشکیل می دهند، زیرا ما چندین
63
00:02:53,650 –> 00:02:57,000
ورودی داریم، بنابراین می توانیم
64
00:02:57,000 –> 00:03:01,150
پایتون را به راحتی هدایت کنیم تا هر ورودی را بگیرد و آنها را
65
00:03:01,150 –> 00:03:03,640
به یک ماشین جداگانه بدهد و از این طریق به ما کمک کند
66
00:03:03,640 –> 00:03:06,010
تا کارها را تسریع کنیم و ما حتی میتوان
67
00:03:06,010 –> 00:03:08,410
نتایج را دوباره به ترتیب صحیح جمعآوری کرد،
68
00:03:08,410 –> 00:03:10,690
زیرا در غیر این صورت انجام این
69
00:03:10,690 –> 00:03:12,840
کار برای رایانه کار واضحی
70
00:03:12,840 –> 00:03:15,040
نیست، بیایید
71
00:03:15,040 –> 00:03:17,620
برای این آموزش شروع کنیم، من
72
00:03:17,620 –> 00:03:19,660
در ژنوم انسان تکرار میکنم و
73
00:03:19,660 –> 00:03:22,269
وقوع همه k-mers را میشمارم.
74
00:03:22,269 –> 00:03:25,239
با طول 5، ژنوم انسان دارای
75
00:03:25,239 –> 00:03:27,700
ورودی های کافی است که به ما امکان می
76
00:03:27,700 –> 00:03:30,180
دهد مزایای استفاده از موازی سازی را ببینیم،
77
00:03:30,180 –> 00:03:33,100
اما البته این مفهوم برای
78
00:03:33,100 –> 00:03:35,440
هر فایل سریع یا هر ژنومی صدق می کند.
79
00:03:35,440 –> 00:03:38,049
لازم نیست ژنوم انسان وجود داشته باشد، بنابراین
80
00:03:38,049 –> 00:03:39,970
برای پیوند به همان فایل سریعتر وارد توضیحات شوید،
81
00:03:39,970 –> 00:03:41,680
اگر میخواهید
82
00:03:41,680 –> 00:03:44,980
ابتدا آن را دنبال کنید، ما
83
00:03:44,980 –> 00:03:46,720
همه کتابخانهها را وارد میکنیم و فقط به
84
00:03:46,720 –> 00:03:49,690
تعداد کمی نیاز داریم که
85
00:03:49,690 –> 00:03:53,500
وارد خواهیم کرد. زمان OSCE و سپس از
86
00:03:53,500 –> 00:03:54,970
لب بالا چون ما قرار نیست
87
00:03:54,970 –> 00:03:58,950
همه چیز را از واردات شکلات به
88
00:03:58,950 –> 00:04:05,560
صورت موازی و با تاخیر وارد کنیم، در واقع یک ماژول
89
00:04:05,560 –> 00:04:10,019
در اینجا می تواند از شمارنده واردات مجموعه ها ببیند
90
00:04:10,019 –> 00:04:12,970
و خواهید دید که چرا بعدا
91
00:04:12,970 –> 00:04:15,579
البته به یاد داشته باشید که من به شما گفتم یک
92
00:04:15,579 –> 00:04:17,738
فایل سریعتر معمولا از
93
00:04:17,738 –> 00:04:20,289
چندین ورودی تشکیل شده است و هر
94
00:04:20,289 –> 00:04:23,470
ورودی با نماد بزرگتر از نشان داده می شود، اگر
95
00:04:23,470 –> 00:04:25,780
لیستی تهیه کنیم که نشان دهد ورودی چه زمانی
96
00:04:25,780 –> 00:04:28,120
شروع و چه زمانی پایان می یابد، می توانیم به راحتی و سریع
97
00:04:28,120 –> 00:04:30,819
وظایف جدید را به هر دوره موجود اختصاص دهیم،
98
00:04:30,819 –> 00:04:34,090
بنابراین این موقعیت صفر خواهد بود و
99
00:04:34,090 –> 00:04:37,630
ممکن است این باشد. موقعیت 300 یا هر چیز دیگری در یک
100
00:04:37,630 –> 00:04:40,539
سند، پس ما موقعیت 301 را
101
00:04:40,539 –> 00:04:43,690
خواهیم داشت و سپس موقعیت 600 یا
102
00:04:43,690 –> 00:04:46,300
چیزی شبیه به این را خواهیم داشت که تولید این
103
00:04:46,300 –> 00:04:48,669
شاخص ها معمولاً از
104
00:04:48,669 –> 00:04:50,979
نظر سرعت گلوگاه نیستند. با
105
00:04:50,979 –> 00:04:53,169
خیال راحت این محاسبات را به هر شکلی که می خواهید انجام دهید،
106
00:04:53,169 –> 00:04:54,849
من یکی از سریع ترین روش هایی را
107
00:04:54,849 –> 00:04:57,580
که با آن آشنا هستم به شما نشان خواهم داد، اما نترسید زیرا
108
00:04:57,580 –> 00:04:59,830
این ربطی به
109
00:04:59,830 –> 00:05:01,810
خود موازی سازی ندارد،
110
00:05:01,810 –> 00:05:03,960
مرحله موازی سازی بسیار ساده تر است
111
00:05:03,960 –> 00:05:06,699
. اولین کاری که میخواهیم انجام دهیم این است که
112
00:05:06,699 –> 00:05:09,220
تابعی بنویسیم که بتواند یک فایل FASTA را باز کند و
113
00:05:09,220 –> 00:05:17,199
سپس مانند آنچه که به شما نشان دادم ایندکس کند، بنابراین
114
00:05:17,199 –> 00:05:20,169
فهرستسازی سریعتری را تعریف میکنیم که
115
00:05:20,169 –> 00:05:24,419
نام فایل را به عنوان ورودی به FASTA میگیرد،
116
00:05:32,700 –> 00:05:34,770
سپس میخواهیم فایل را به صورت باز کنیم. یک
117
00:05:34,770 –> 00:05:37,920
باینری زیرا خواندن در باینری
118
00:05:37,920 –> 00:05:40,440
معمولاً همیشه سریعتر است و ما
119
00:05:40,440 –> 00:05:46,370
آن فایل باز را به متغیر موجود در فایل اختصاص میدهیم،
120
00:05:58,970 –> 00:06:01,260
بنابراین کار بعدی که انجام دادم این است که
121
00:06:01,260 –> 00:06:04,550
در واقع اندازه یک قطعه را 1024 تعریف
122
00:06:04,550 –> 00:06:08,280
کنم ابتدا به پایتون گفتم سریعتر من را به
123
00:06:08,280 –> 00:06:11,190
صورت باینری باز کند و در مرحله بعد، من یک اندازه قطعه را تنظیم کردم، به
124
00:06:11,190 –> 00:06:14,670
این معنی که هر بار که در حال
125
00:06:14,670 –> 00:06:16,710
خواندن یک قطعه از فایل
126
00:06:16,710 –> 00:06:18,870
هستم، این قطعه را میگیرم و خواندن به صورت تکهای در
127
00:06:18,870 –> 00:06:20,670
واقع یکی از سریعترین راهها پس از
128
00:06:20,670 –> 00:06:23,910
اینکه به شما اختصاص داده شد،
129
00:06:23,910 –> 00:06:26,250
خواندن باینری را در اینجا میدانید و میدانید. این واقعاً
130
00:06:26,250 –> 00:06:27,600
مهم است نکته ای که باید هنگام خواندن
131
00:06:27,600 –> 00:06:46,260
فایل ها در محاسبات با کارایی بالا بدانیم، بنابراین
132
00:06:46,260 –> 00:06:48,510
اکنون من شروع به تعریف یک حلقه برای
133
00:06:48,510 –> 00:06:50,700
خواندن کل محتوای فایل FASTA کرده ام
134
00:06:50,700 –> 00:06:54,600
و زمانی که طول آن صفر شد، در ادامه
135
00:06:54,600 –> 00:06:56,930
136
00:07:22,600 –> 00:07:25,400
با جستجوی
137
00:07:25,400 –> 00:07:29,060
سرصفحه هایی شروع می کنیم. با علامت
138
00:07:29,060 –> 00:07:31,130
بزرگتر از نشان داده می شوند، بنابراین همه ما
139
00:07:31,130 –> 00:07:33,740
محتوا را می گوییم و از تابع Find استفاده می کنیم و
140
00:07:33,740 –> 00:07:35,720
به دنبال نمایش دودویی
141
00:07:35,720 –> 00:07:37,760
علامت بزرگتر می گردیم و سپس
142
00:07:37,760 –> 00:08:21,320
به فهرست شروع اضافه می کنیم و به
143
00:08:21,320 –> 00:08:22,910
همان روشی که متوجه شدیم سرصفحه از کجا
144
00:08:22,910 –> 00:08:25,370
شروع می شود. ما همچنین تعیین می کنیم
145
00:08:25,370 –> 00:08:28,310
که سرصفحه به کجا ختم می شود، بنابراین یک بار دیگر
146
00:08:28,310 –> 00:08:30,980
به محتوا نگاه می کنیم و می یابیم که
147
00:08:30,980 –> 00:08:35,929
باینری بک اسلش در کجا وجود دارد و سپس
148
00:08:35,929 –> 00:08:39,380
می توانیم آن را به لیست انتهایی یا head end اضافه کنیم
149
00:08:39,380 –> 00:08:41,809
و پس از آن بسیار مهم است که به یاد داشته باشید
150
00:08:41,809 –> 00:08:43,039
که فایل را ببندید
151
00:08:43,039 –> 00:08:45,650
زیرا اگر روی یک فایل ژنومی حلقه بزنید
152
00:08:45,650 –> 00:08:47,780
که متنی چند گیگابایتی است
153
00:08:47,780 –> 00:08:51,020
و آن را برای هر بار
154
00:08:51,020 –> 00:08:53,089
ورودی در FASTA خود باز کنید، ممکن است به
155
00:08:53,089 –> 00:08:54,800
شدت سطح شیب دار خود را بیش از حد بارگذاری کنید، بنابراین
156
00:08:54,800 –> 00:08:57,530
به یاد داشته باشید که پس از این فایل را ببندید.
157
00:08:57,530 –> 00:09:00,430
حلقه
158
00:09:49,350 –> 00:09:51,730
بعدی من قطعه ای را وارد کرده ام که
159
00:09:51,730 –> 00:09:56,140
به دنبال سرصفحه های اشتباه می شود، بله،
160
00:09:56,140 –> 00:09:58,810
اساساً به این معنی است که
161
00:09:58,810 –> 00:10:00,670
ما در خط سرصفحه خود یک نماد بیشتر از
162
00:10:00,670 –> 00:10:05,170
آن داریم و سپس به سادگی ادامه می دهیم و
163
00:10:05,170 –> 00:10:10,000
سپس این شاخص را حذف می کنیم و در
164
00:10:10,000 –> 00:10:12,330
نهایت پس از اینکه به شما رسیدیم.
165
00:10:12,330 –> 00:10:15,700
جایی که هدر به پایان می رسد و شروع می شود، سپس اگر
166
00:10:15,700 –> 00:10:18,190
مقدار یک را اضافه کنیم که
167
00:10:18,190 –> 00:10:21,130
یک دقت بعد از پایان سرصفحه
168
00:10:21,130 –> 00:10:23,620
خواهد بود، در واقع به جایی می رویم
169
00:10:23,620 –> 00:10:25,120
که دنباله شروع می شود و همانطور
170
00:10:25,120 –> 00:10:28,720
که در word document به شما نشان دادم و
171
00:10:28,720 –> 00:10:30,400
همین طور برای جایی که دنباله شروع می شود
172
00:10:30,400 –> 00:10:32,620
اگر مقدار یک را کم کنیم و
173
00:10:32,620 –> 00:10:35,620
اکنون به انتهای یک دنباله برمی گردیم، بنابراین اکنون ادامه دهید
174
00:10:35,620 –> 00:10:37,780
و این مقادیر را به لیستی
175
00:10:37,780 –> 00:10:41,370
به نام شاخص FASTA اضافه کنید،
176
00:10:41,370 –> 00:10:43,750
موقعیت ستاره دنباله
177
00:10:43,750 –> 00:10:46,030
را اضافه کنید و موقعیت دنباله را اضافه کنید.
178
00:10:46,030 –> 00:10:48,970
پایان و در نهایت با کم کردن
179
00:10:48,970 –> 00:10:51,640
دنباله شروع از انتهای دنباله
180
00:10:51,640 –> 00:10:54,190
، در واقع اندازه این
181
00:10:54,190 –> 00:10:56,830
سکانس ها را خواهید دید و این در یک لحظه مفید خواهد بود
182
00:10:56,830 –> 00:10:59,550
،
183
00:11:10,570 –> 00:11:13,250
بنابراین کاری که من اکنون انجام داده ام بسیار ساده است.
184
00:11:13,250 –> 00:11:16,250
خطی که تمام اندازهها را بررسی میکند
185
00:11:16,250 –> 00:11:19,100
و سپس آنها را مرتب میکند و
186
00:11:19,100 –> 00:11:21,170
دلیل اینکه ما میخواهیم آنها را مرتب کنیم این است
187
00:11:21,170 –> 00:11:23,600
که همه دورهها را به همان اندازه
188
00:11:23,600 –> 00:11:27,200
که میتوانید تصور کنید یک ماشین
189
00:11:27,200 –> 00:11:29,630
بعد از این همه هزینه کار واقعاً بزرگی دارد، انجام شود.
190
00:11:29,630 –> 00:11:32,600
ماشینهای دیگر دویدن را انجام دادهاند، سپس
191
00:11:32,600 –> 00:11:34,580
هیچ چیز نمیتواند پیشرفت کند تا آخرین
192
00:11:34,580 –> 00:11:37,040
آکورد انجام شود، بنابراین بسیار مهم است
193
00:11:37,040 –> 00:11:42,440
که همه این کارها را متعادل کنیم و در نهایت ما
194
00:11:42,440 –> 00:11:47,360
شاخص FASTA را برمیگردانیم، بنابراین
195
00:11:47,360 –> 00:11:50,240
اولین تابعی که در حال
196
00:11:50,240 –> 00:11:53,990
خواندن یک فایل به صورت باینری هستیم، در حال خواندن
197
00:11:53,990 –> 00:11:55,910
آن به پایان میرسد. در تکههایی با اندازه تکهای که
198
00:11:55,910 –> 00:11:58,910
تعریف کردهایم و آن را میخوانیم تا زمانی
199
00:11:58,910 –> 00:12:00,950
که دیگر چیزی برای خواندن وجود نداشته باشد، کاری که
200
00:12:00,950 –> 00:12:02,870
انجام میدهیم این است که به دنبال سرصفحههایی باشیم که
201
00:12:02,870 –> 00:12:05,030
با علامت بزرگتر نشان داده شده است و
202
00:12:05,030 –> 00:12:08,660
سپس متوجه میشویم که به کجا ختم میشوند، سپس
203
00:12:08,660 –> 00:12:11,360
سرصفحههای اشتباه را حذف میکنیم. و سپس
204
00:12:11,360 –> 00:12:13,520
205
00:12:13,520 –> 00:12:16,280
زمانی که آن ها را به لیستی به نام شاخص FASTA اضافه می کنیم، شروع و پایان دنباله را تعیین می کنیم
206
00:12:16,280 –> 00:12:18,440
و این
207
00:12:18,440 –> 00:12:20,810
تابع متعادل کننده بار است که
208
00:12:20,810 –> 00:12:23,360
به عدد سوم در تاپل نگاه می کند، بنابراین اکنون
209
00:12:23,360 –> 00:12:25,190
فکر می کنم که s را می سازد. ense سعی کنید و
210
00:12:25,190 –> 00:12:26,839
این تابع را اجرا کنید تا بتوانید ببینید
211
00:12:26,839 –> 00:12:29,839
خروجی به چه شکل است و ما
212
00:12:29,839 –> 00:12:31,780
قسمت اصلی یک کد را با بلوک اصلی
213
00:12:31,780 –> 00:12:38,480
در اینجا می نویسیم و دلیل اینکه چرا می خواهیم
214
00:12:38,480 –> 00:12:40,610
اجرا کنیم یا کدی شبیه به این را داریم در واقع به
215
00:12:40,610 –> 00:12:43,790
راه اندازی مربوط می شود. پردازندههای کودک
216
00:12:43,790 –> 00:12:50,390
بعداً من یک فایل آزمایشی کوچک
217
00:12:50,390 –> 00:12:52,690
از دیش از ژنوم انسان دارم و
218
00:12:52,690 –> 00:12:56,240
این یک فایل آزمایشی بسیار کوچک است همانطور که
219
00:12:56,240 –> 00:12:58,100
در یک لحظه خواهید دید، اما فقط برای این است که به شما نشان دهم
220
00:12:58,100 –> 00:13:00,020
چه نوع خروجی را میخواهیم
221
00:13:00,020 –> 00:13:02,870
دریافت کنیم. بالا بروید و طول پادشاه خود را مشخص کنید
222
00:13:02,870 –> 00:13:05,900
، بنابراین بیایید طول
223
00:13:05,900 –> 00:13:08,410
224
00:13:13,330 –> 00:13:15,530
بعدی را
225
00:13:15,530 –> 00:13:18,560
5 تعیین
226
00:13:18,560 –> 00:13:20,630
227
00:13:20,630 –> 00:13:22,730
228
00:13:22,730 –> 00:13:24,860
کنیم. زمانی که
229
00:13:24,860 –> 00:13:27,110
DNA را مرور می کنیم و
230
00:13:27,110 –> 00:13:28,610
همه آنها را به یک کاراکتر تبدیل می کند
231
00:13:28,610 –> 00:13:30,920
که سرمایه است و در این
232
00:13:30,920 –> 00:13:35,240
مورد و atcg بزرگی که می خواهیم
233
00:13:35,240 –> 00:13:39,820
نگه داریم، فقط آنها را به حروف کوچک تبدیل
234
00:13:42,550 –> 00:13:45,320
می کنم، متغیری به نام worker اختصاص داده ام.
235
00:13:45,320 –> 00:13:48,770
بنابراین حالت سیستم عامل ule
236
00:13:48,770 –> 00:13:50,840
در واقع تابعی به نام CPU count
237
00:13:50,840 –> 00:13:54,650
دارد که وارد سیستم شما میشود و
238
00:13:54,650 –> 00:13:56,240
تعداد هستههای منطقی
239
00:13:56,240 –> 00:13:59,210
در اختیار شما را میخواند، بنابراین
240
00:13:59,210 –> 00:14:01,280
حداکثر تعداد هستههای منطقی در
241
00:14:01,280 –> 00:14:04,730
سیستم شما است که لزوماً به آن نیاز نداریم
242
00:14:04,730 –> 00:14:06,800
، اما خوب است که بدانید و ما
243
00:14:06,800 –> 00:14:09,980
در یک لحظه وارد آن خواهیم شد، بنابراین بیایید اکنون
244
00:14:09,980 –> 00:14:13,280
پیش برویم و سعی کنیم و در نهایت
245
00:14:13,280 –> 00:14:26,990
نمایه های فایل آزمایشی را برگردانیم، بنابراین به
246
00:14:26,990 –> 00:14:28,790
خاطر داشته باشید که این قسمت موازی نیست،
247
00:14:28,790 –> 00:14:31,760
اما بعداً اتفاق می افتد و همچنین توجه داشته باشید
248
00:14:31,760 –> 00:14:33,560
که من همه چیز را زمان بندی می کنم این یک عادت واقعاً خوب
249
00:14:33,560 –> 00:14:35,950
است که به شما کمک میکند تا
250
00:14:35,950 –> 00:14:38,120
بعداً گلوگاههای کد خود را شناسایی کنید، در
251
00:14:38,120 –> 00:14:42,530
مورد اینکه کدام قسمتهای کد
252
00:14:42,530 –> 00:14:44,660
پردازش زمان زیادی را صرف
253
00:14:44,660 –> 00:14:47,210
پردازش میکنند و بله، پس بیایید با
254
00:14:47,210 –> 00:14:49,790
چاپ کردن مدت زمان آن پایان دهیم و سعی کنیم
255
00:14:49,790 –> 00:14:55,850
آن را اجرا کنیم. و من می بینم که ما یک خطا دریافت می کنیم بله
256
00:14:55,850 –> 00:14:58,520
ما فقط باید یک براکت اضافی را
257
00:14:58,520 –> 00:15:00,170
در اینجا اضافه کنیم زیرا ما در حال
258
00:15:00,170 –> 00:15:04,190
ساختن تاپل هایی هستیم که به
259
00:15:04,190 –> 00:15:09,520
لیست فستا اضافه می کنیم و همچنین متوجه نکته
260
00:15:09,520 –> 00:15:13,250
مهمی شدم همچنین بله ما باید
261
00:15:13,250 –> 00:15:18,660
این را به l منتقل کنیم. eft چون
262
00:15:18,660 –> 00:15:22,449
بعد از اینکه بعد از انجام این حلقه دیگر محتوایی وجود ندارد
263
00:15:22,449 –> 00:15:24,730
زمانی است که می خواهیم
264
00:15:24,730 –> 00:15:27,930
از فایل عبور کنیم البته من قبل از
265
00:15:27,930 –> 00:15:32,199
آن نیستم بنابراین دنبال انتهای سرصفحه آماده می
266
00:15:32,199 –> 00:15:36,129
گردیم و سپس می بندیم اجازه دهید یک بار دیگر کد را اجرا
267
00:15:36,129 –> 00:15:40,569
کنیم و فکر میکنم
268
00:15:40,569 –> 00:15:47,079
اگر متغیر فهرست من را باز کنم
269
00:15:47,079 –> 00:15:51,449
، لیستی داریم که حاوی چند تاپل است و
270
00:15:51,449 –> 00:15:55,769
آنها باید بر اساس بزرگترین
271
00:15:55,769 –> 00:16:00,399
ورودی سریعتر و کوچکترین بدی من –
272
00:16:00,399 –> 00:16:05,649
بزرگترین ورودی مرتب شوند و در اینجا فایل ادعا میکند
273
00:16:05,649 –> 00:16:09,819
که ما 30 داریم زیرا صفر داریم. ایندکس
274
00:16:09,819 –> 00:16:13,660
کردن 30 ورودی است و من اتفاقاً
275
00:16:13,660 –> 00:16:16,809
فایل آزمایشی را در اطراف دارم، بنابراین این چیزی است که یک
276
00:16:16,809 –> 00:16:20,139
فایل FASTA به نظر می رسد و ما
277
00:16:20,139 –> 00:16:23,620
هدر را داریم البته این دنباله 1
278
00:16:23,620 –> 00:16:26,800
اولین سکانس است و اجازه دهید
279
00:16:26,800 –> 00:16:28,509
تا آنجا به پایین بروید زیرا
280
00:16:28,509 –> 00:16:31,029
میدانم که میتوانم آخرین ورودی
281
00:16:31,029 –> 00:16:36,430
را اینجا و آنجا پیدا کنم. به دنباله xxx xxx میرویم،
282
00:16:36,430 –> 00:16:39,309
بیایید به همه این فهرست
283
00:16:39,309 –> 00:16:42,870
برگردیم و ما در واقع 30 ورودی داریم و
284
00:16:42,870 –> 00:16:46,389
آنها از کوچکترین به
285
00:16:46,389 –> 00:16:50,019
بزرگترین معنی مرتب شدهاند نه به یک ترتیب، بلکه
286
00:16:50,019 –> 00:16:55,660
به ترتیب اندازه خوب است اکنون ما
287
00:16:55,660 –> 00:16:58,120
اساساً آماده شروع یافتن یا
288
00:16:58,120 –> 00:17:01,569
k-mers هستیم و من شروع به نوشتن یک
289
00:17:01,569 –> 00:17:08,380
تابع جدید برای این منظور خواهم کرد
290
00:17:08,380 –> 00:17:11,470
یا FASTA آزمایش انسانی را در
291
00:17:11,470 –> 00:17:13,990
این مورد ثبت می کند و شاخص هایی را می گیرد که
292
00:17:13,990 –> 00:17:18,039
ما به تازگی توانسته ایم یکی را بدست آوریم.
293
00:17:18,039 –> 00:17:21,449
در این مورد من را index نامید،
294
00:17:41,830 –> 00:17:45,650
بنابراین یک بار دیگر فایل FASTA
295
00:17:45,650 –> 00:17:48,830
را با استفاده از تابع باز باز می کنیم و
296
00:17:48,830 –> 00:17:53,120
به صورت باینری می خوانیم.
297
00:17:53,120 –> 00:17:55,180
298
00:17:55,180 –> 00:17:58,070
299
00:17:58,070 –> 00:18:00,320
pon
300
00:18:00,320 –> 00:18:03,310
chernow من در هر جایی از سند است و
301
00:18:03,310 –> 00:18:05,480
این همان موقعیتی است که قرار است آن را در آن
302
00:18:05,480 –> 00:18:08,750
قرار دهد و آن موقعیت شاخصی است که ما
303
00:18:08,750 –> 00:18:10,730
از تابع بالا به دست آوردیم
304
00:18:10,730 –> 00:18:16,550
و سپس از خواندن استفاده می کند و آنچه
305
00:18:16,550 –> 00:18:18,140
قرار است خوانده شود اساساً تمام
306
00:18:18,140 –> 00:18:21,170
محتوای بین اینها است. دو شاخص و
307
00:18:21,170 –> 00:18:23,330
قرار است آن را به متغیری
308
00:18:23,330 –> 00:18:26,360
به نام sequence اختصاص دهد، اما قبل از انجام این کار،
309
00:18:26,360 –> 00:18:29,420
از جدول ترجمه نیز استفاده می کنیم که
310
00:18:29,420 –> 00:18:31,670
از شر تمام کاراکترهای ناخواسته ای
311
00:18:31,670 –> 00:18:34,610
که ممکن است رابط فایل باشند، خلاص می شود.
312
00:18:34,610 –> 00:18:37,240
در اینجا مراقب مواردی مانند
313
00:18:37,240 –> 00:18:40,880
پرش از خطوط باشید و در آخر باید
314
00:18:40,880 –> 00:18:43,880
به یاد داشته باشید که فایل را ببندید
315
00:18:43,880 –> 00:18:47,030
و دلیل آن این است که فایل DNA شما
316
00:18:47,030 –> 00:18:49,460
ممکن است فضای زیادی را اشغال کند و
317
00:18:49,460 –> 00:18:52,550
30 بار آن را باز می کند
318
00:18:52,550 –> 00:18:55,610
زیرا ما 30 ورودی داریم. بنابراین خیلی سریع حافظه زیادی را می خورد،
319
00:18:55,610 –> 00:18:58,700
بنابراین به یاد داشته باشید که به
320
00:18:58,700 –> 00:19:03,500
سادگی نقطه را نزدیک به بالا قرار دهید، ما
321
00:19:03,500 –> 00:19:06,950
یک فرهنگ لغت فرعی را برای
322
00:19:06,950 –> 00:19:09,260
پیگیری همه k-merهایی که با
323
00:19:09,260 –> 00:19:12,950
هر یک از آنها یک فرآیند موازی پیدا می کنیم اختصاص می دهیم و
324
00:19:12,950 –> 00:19:14,870
بعد در واقع یک فرهنگ دیگر وجود دارد. ترفند
325
00:19:14,870 –> 00:19:17,150
آستین ما که می توانیم از آن برای
326
00:19:17,150 –> 00:19:20,090
صرفه جویی در زمان استفاده کنیم زیرا معمولاً
327
00:19:20,090 –> 00:19:23,330
فایل های DNA بزرگ حاوی تعداد زیادی نوکلئوتید تعریف نشده است
328
00:19:23,330 –> 00:19:26,030
که در اینجا انتهای آنهاست
329
00:19:26,030 –> 00:19:28,610
. امیدوارم بتوانید این را ببینید اما
330
00:19:28,610 –> 00:19:30,770
اساساً ما دنباله خود را شروع می کنیم
331
00:19:30,770 –> 00:19:33,650
و سپس تعداد زیادی از آنها تعریف نشده است. نوکلئوتیدها
332
00:19:33,650 –> 00:19:36,950
فقط دو خط نیستند بلکه می توانند
333
00:19:36,950 –> 00:19:39,950
صدها خط در یک فایل DNA واقعی باشند و
334
00:19:39,950 –> 00:19:42,290
دلیلی وجود ندارد که کامپیوتر
335
00:19:42,290 –> 00:19:44,300
واقعاً به دنبال گوش در
336
00:19:44,300 –> 00:19:46,520
آن ناحیه باشد زیرا
337
00:19:46,520 –> 00:19:49,310
به هر حال مفید نخواهد بود، بنابراین بیایید تعریف کنیم. تابعی است که
338
00:19:49,310 –> 00:19:53,360
می تواند از همه آن مناط