در این مطلب، ویدئو برازش توزیع های گسسته به داده ها با SciPy (Python) با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 00:23:45
تصاویر این ویدئو:



قسمتی از زیرنویس این فیلم:
00:00:00,560 –> 00:00:02,080
سلام به همگی متشکریم که
2
00:00:02,080 –> 00:00:04,000
این ویدیو را بررسی کردید، بنابراین این یک
3
00:00:04,000 –> 00:00:06,399
ویدیوی دیگر در این سری ام است که من در مورد
4
00:00:06,399 –> 00:00:08,000
تخمین پارامتر می سازم
5
00:00:08,000 –> 00:00:10,240
و این در واقع دنباله ای بر
6
00:00:10,240 –> 00:00:12,160
ویدیوی دیگری است که من ساخته ام، بنابراین
7
00:00:12,160 –> 00:00:15,839
قبلاً این ویدیو را در مورد نحوه استفاده ساخته ام um scipy
8
00:00:15,839 –> 00:00:18,400
برای تخمین پارامترهای
9
00:00:18,400 –> 00:00:20,400
توزیع های احتمالی
10
00:00:20,400 –> 00:00:22,720
um بنابراین من آن ویدیو را ساختم و امم گروهی
11
00:00:22,720 –> 00:00:25,920
از نظر دهندگان به این نکته اشاره کردند که روشی
12
00:00:25,920 –> 00:00:28,240
که برای انجام کارها در آن ویدیو توضیح دادم
13
00:00:28,240 –> 00:00:29,119
14
00:00:29,119 –> 00:00:31,760
فقط برای توزیع های مداوم
15
00:00:31,760 –> 00:00:34,239
در علمی تخیلی کار می کند و کار نمی کند. برای um
16
00:00:34,239 –> 00:00:36,640
توزیع های گسسته، بنابراین فقط به
17
00:00:36,640 –> 00:00:38,559
شما بچه ها یادآوری می کنم که
18
00:00:38,559 –> 00:00:40,800
توزیع های پیوسته این
19
00:00:40,800 –> 00:00:41,920
20
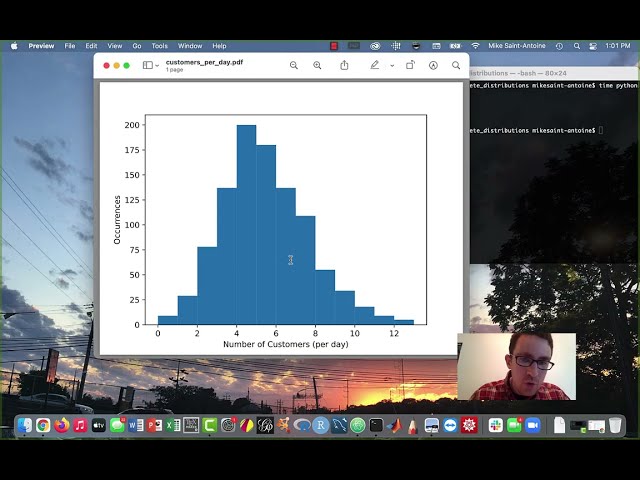
00:00:41,920 –> 00:00:44,480
روش بسیار آسان را دارند که می توانید در scipy از آن استفاده کنید که به
21
00:00:44,480 –> 00:00:46,559
آن روش um fit نامیده می شود
22
00:00:46,559 –> 00:00:48,640
که می توانید
23
00:00:48,640 –> 00:00:51,039
به راحتی از آن برای تطبیق توزیع با
24
00:00:51,039 –> 00:00:52,320
مجموعه داده های خود استفاده کنید.
25
00:00:52,320 –> 00:00:54,320
بنابراین در ویدیوی قبلی خود من به شما بچه ها نشان دادم که
26
00:00:54,320 –> 00:00:56,640
چگونه از این روش استفاده کنید، اما همانطور
27
00:00:56,640 –> 00:00:59,120
که نظر دهندگان اشاره کردند
28
00:00:59,120 –> 00:01:00,719
من متوجه نشدم که
29
00:01:00,719 –> 00:01:03,440
scipy فقط برای
30
00:01:03,440 –> 00:01:05,920
توزیع های پیوسته و برای توزیع های گسسته این روش را
31
00:01:05,920 –> 00:01:07,520
دارد.
32
00:01:07,520 –> 00:01:09,600
33
00:01:09,600 –> 00:01:11,520
آنها این
34
00:01:11,520 –> 00:01:13,040
روش را
35
00:01:13,040 –> 00:01:14,720
ندارند، بنابراین
36
00:01:14,720 –> 00:01:16,640
خیلی آره، انجام آن
37
00:01:16,640 –> 00:01:18,320
را برای توزیع های پیوسته بسیار آسان می کنند،
38
00:01:18,320 –> 00:01:19,680
اما برای توزیع های گسسته،
39
00:01:19,680 –> 00:01:21,759
ما باید
40
00:01:21,759 –> 00:01:24,159
تخمین پارامتر را خودمان انجام دهیم،
41
00:01:24,159 –> 00:01:25,759
بنابراین این ویدیو نمایش داده می شود. شما
42
00:01:25,759 –> 00:01:27,600
بچه ها چگونه تخمین پارامتر را
43
00:01:27,600 –> 00:01:28,880
44
00:01:28,880 –> 00:01:31,280
برای یک توزیع احتمال مانند یک
45
00:01:31,280 –> 00:01:32,880
نوع از ابتدا
46
00:01:32,880 –> 00:01:35,920
انجام دهیم اگر این روش مناسب مناسب را نداریم
47
00:01:35,920 –> 00:01:38,159
که اوم آن topi برای توزیع های پیوسته به ما می دهد
48
00:01:38,159 –> 00:01:40,320
،
49
00:01:40,320 –> 00:01:42,000
بنابراین به شما بچه ها نشان خواهیم داد که بله چگونه
50
00:01:42,000 –> 00:01:44,079
چگونه می توان آن را از ابتدا انجام داد، به
51
00:01:44,079 –> 00:01:45,920
گونه ای که
52
00:01:45,920 –> 00:01:47,520
برای هر نوع توزیعی، حتی
53
00:01:47,520 –> 00:01:49,520
توزیع های گسسته،
54
00:01:49,520 –> 00:01:51,840
کارساز باشد، بسیار خوب، بنابراین من تنظیم می کنم، به
55
00:01:51,840 –> 00:01:53,600
شما دوستانی مانند مجموعه داده نمونه ای که در مورد آن صحبت می کنیم ارائه خواهم کرد.
56
00:01:53,600 –> 00:01:55,840
در اینجا،
57
00:01:55,840 –> 00:01:59,200
پس فرض کنید که اوم، شما صاحب رستوران هستید
58
00:01:59,200 –> 00:02:02,079
و هر روز
59
00:02:02,079 –> 00:02:03,520
تعداد مشتریانی که به رستوران شما می آیند را می
60
00:02:03,520 –> 00:02:04,640
61
00:02:04,640 –> 00:02:06,560
شمارید، و برای ایجاد یک
62
00:02:06,560 –> 00:02:08,639
فرض ساده، فقط بگوییم
63
00:02:08,639 –> 00:02:09,598
64
00:02:09,598 –> 00:02:11,520
که تنها تفاوت بین روزها
65
00:02:11,520 –> 00:02:14,000
نوسان تصادفی است،
66
00:02:14,000 –> 00:02:16,319
هیچ روزی وجود ندارد که بیشتر شلوغ یا کمتر
67
00:02:16,319 –> 00:02:19,520
شلوغ باشد به عنوان بخشی از یک الگو، فقط
68
00:02:19,520 –> 00:02:20,480
69
00:02:20,480 –> 00:02:22,800
نوسانات تصادفی تصادفی بین روزها است
70
00:02:22,800 –> 00:02:24,720
اما بله، بنابراین هر روز شمارش می کنید که چه
71
00:02:24,720 –> 00:02:27,040
تعداد مشتری به رستوران شما می آیند.
72
00:02:27,040 –> 00:02:29,599
و سپس شما
73
00:02:29,599 –> 00:02:31,680
این نمودار از داده های خود را پس از جمع آوری به
74
00:02:31,680 –> 00:02:34,000
مدت سه سال یا بیشتر می سازید
75
00:02:34,000 –> 00:02:35,920
و سپس این
76
00:02:35,920 –> 00:02:38,080
تعداد روزهایی است که برای
77
00:02:38,080 –> 00:02:39,760
هر ام ام
78
00:02:39,760 –> 00:02:41,519
برای هر تعداد ممکن مشتری شمارش کرده اید،
79
00:02:41,519 –> 00:02:43,599
بنابراین می گوید که مانند این این است که
80
00:02:43,599 –> 00:02:47,120
شما چند روز um صفر مشتری داشتید و سپس
81
00:02:47,120 –> 00:02:48,560
یک مشتری
82
00:02:48,560 –> 00:02:50,480
ام و سپس این چند روز بود که
83
00:02:50,480 –> 00:02:53,519
دو مشتری مانند 75 روز
84
00:02:53,519 –> 00:02:55,440
ام و غیره و غیره
85
00:02:55,440 –> 00:02:57,440
86
00:02:57,440 –> 00:02:58,480
87
00:02:58,480 –> 00:03:01,760
داشتید، بنابراین این یک توزیع گسسته است زیرا نمی توانید مانند 2.3
88
00:03:01,760 –> 00:03:03,920
مشتری داشته باشید. یک روز میدانید
89
00:03:03,920 –> 00:03:07,519
منظور من چیست، همه این نقاط داده um
90
00:03:07,519 –> 00:03:08,720
اعداد صحیح هستند،
91
00:03:08,720 –> 00:03:10,640
بنابراین این چیزی است که ما آن را توزیع گسسته مینامیم
92
00:03:10,640 –> 00:03:12,159
93
00:03:12,159 –> 00:03:14,319
و اوم،
94
00:03:14,319 –> 00:03:15,840
بنابراین این همان چیزی است که دادهها در واقع به نظر میرسند این همان چیزی است
95
00:03:15,840 –> 00:03:18,080
96
00:03:18,080 –> 00:03:20,640
که همه تعداد ما برای
97
00:03:20,640 –> 00:03:21,840
تمام روزها
98
00:03:21,840 –> 00:03:24,400
این مجموعه دادهها در اینجا است
99
00:03:24,400 –> 00:03:26,879
و سپس باید به این فکر
100
00:03:26,879 –> 00:03:28,720
کنیم که چگونه میخواهیم این را در یک توزیع تطبیق دهیم،
101
00:03:28,720 –> 00:03:30,000
102
00:03:30,000 –> 00:03:30,879
بنابراین
103
00:03:30,879 –> 00:03:32,720
این نقطهای
104
00:03:32,720 –> 00:03:34,720
است که در واقع سختترین
105
00:03:34,720 –> 00:03:36,959
بخش این نوع um است.
106
00:03:36,959 –> 00:03:38,799
این نوع کار این است که شما نیاز به ایجاد
107
00:03:38,799 –> 00:03:40,560
نوعی شهود
108
00:03:40,560 –> 00:03:42,879
برای اینکه از چه توزیعی حتی
109
00:03:42,879 –> 00:03:44,959
در وهله اول باید استفاده کنید، دارید،
110
00:03:44,959 –> 00:03:46,560
بنابراین
111
00:03:46,560 –> 00:03:47,920
در این مورد، ما از چیزی به
112
00:03:47,920 –> 00:03:50,000
نام توزیع پواسون استفاده میکنیم، بنابراین از
113
00:03:50,000 –> 00:03:52,480
توزیع سم برای شمارش استفاده
114
00:03:52,480 –> 00:03:54,799
میکنیم. تعداد رخدادهای تصادفی
115
00:03:54,799 –> 00:03:57,360
یا در یک بازه زمانی یا در یک
116
00:03:57,360 –> 00:04:00,000
فضای فیزیکی، برای مثال
117
00:04:00,000 –> 00:04:02,720
میتوان از توزیع پویسون برای مدلسازی
118
00:04:02,720 –> 00:04:05,200
تعداد
119
00:04:05,200 –> 00:04:07,760
بازدیدکنندگان یک وبسایت در یک روز معین یا مانند
120
00:04:07,760 –> 00:04:09,680
اینکه ما تعداد بازدیدکنندگان را انجام میدهیم استفاده کرد. مشتریان در یک
121
00:04:09,680 –> 00:04:14,720
فروشگاه در یک روز معین یا مثلاً
122
00:04:14,720 –> 00:04:17,358
تعداد تماسهایی که
123
00:04:17,358 –> 00:04:18,639
مرکز تماس دریافت میکند تنها چند
124
00:04:18,639 –> 00:04:21,440
مثال است، اما از توزیع پویسون
125
00:04:21,440 –> 00:04:22,960
برای مدلسازی تعداد رخدادهای تصادفی
126
00:04:22,960 –> 00:04:24,240
127
00:04:24,240 –> 00:04:27,520
که در یک بازه زمانی مشخص
128
00:04:27,520 –> 00:04:31,520
یا یا یک um مانند فضای فیزیکی
129
00:04:31,520 –> 00:04:33,600
ام اما بله، پس این قسمت سخت
130
00:04:33,600 –> 00:04:35,759
است، فقط باید
131
00:04:35,759 –> 00:04:38,000
شهودی را توسعه دهید تا بدانید از کدام
132
00:04:38,000 –> 00:04:39,440
توزیع باید استفاده کنید،
133
00:04:39,440 –> 00:04:41,199
اما برای این یکی فقط به شما می گویم که
134
00:04:41,199 –> 00:04:42,320
ما از توزیع پواسون استفاده می
135
00:04:42,320 –> 00:04:44,080
کنیم زیرا سعی می کنیم
136
00:04:44,080 –> 00:04:46,080
137
00:04:46,080 –> 00:04:47,919
تعداد دفعاتی را که
138
00:04:47,919 –> 00:04:50,000
در یک بازه زمانی اتفاق می افتد مدل کنیم،
139
00:04:50,000 –> 00:04:51,280
140
00:04:51,280 –> 00:04:52,639
اما بله، از توزیع پواسون استفاده می کنیم،
141
00:04:52,639 –> 00:04:54,639
اما بله، مثل این است که گفتم
142
00:04:54,639 –> 00:04:57,759
نمی توانیم از این استفاده کنیم. راحت
143
00:04:57,759 –> 00:05:00,000
ما نمیتوانیم از این روش تناسب راحت استفاده کنیم،
144
00:05:00,000 –> 00:05:01,919
زیرا توزیع پواسون و من
145
00:05:01,919 –> 00:05:03,680
فکر میکنم همه توزیعهای گسسته در
146
00:05:03,680 –> 00:05:06,479
علمی تخیلی این را ندارند، بنابراین باید به
147
00:05:06,479 –> 00:05:08,400
شما بچهها نشان دهم که چگونه میتوانید
148
00:05:08,400 –> 00:05:10,479
از ابتدا و بدون استفاده از دادهها را جابجا کنید.
149
00:05:10,479 –> 00:05:12,800
این روش بسیار ساده ای است که آنها
150
00:05:12,800 –> 00:05:15,919
برای توزیع های پیوسته به ما می دهند،
151
00:05:15,919 –> 00:05:18,160
اما خوب است، بیایید
152
00:05:18,160 –> 00:05:19,520
شروع کنیم،
153
00:05:19,520 –> 00:05:21,120
بنابراین اولین کاری که ما مثل همیشه انجام می دهیم این است
154
00:05:21,120 –> 00:05:23,120
که تمام کتابخانه های ام را که قرار
155
00:05:23,120 –> 00:05:25,520
است استفاده کنند را وارد کنیم، بنابراین
156
00:05:25,520 –> 00:05:29,280
من از اوم استفاده خواهم کرد. matplotlib
157
00:05:29,280 –> 00:05:32,320
از csv libr استفاده کنید ary numpy و سپس در واقع
158
00:05:32,320 –> 00:05:34,479
این کتابخانه ای است که من برای
159
00:05:34,479 –> 00:05:37,360
اهدافی مانند اشکال زدایی استفاده می کنم، اما منظورم این است که ما
160
00:05:37,360 –> 00:05:38,560
در واقع حتی به این نیاز نداریم
161
00:05:38,560 –> 00:05:40,960
تا صادق باشیم،
162
00:05:40,960 –> 00:05:42,560
خب، بنابراین اولین کاری که می خواهیم
163
00:05:42,560 –> 00:05:45,440
انجام دهیم این است که داده ها را بخوانیم. بنابراین من
164
00:05:45,440 –> 00:05:47,280
در اینجا کمی تنبل خواهم بود و فقط
165
00:05:47,280 –> 00:05:48,800
این قسمت از کد را کپی و جایگذاری کنید
166
00:05:48,800 –> 00:05:49,919
زیرا اگر شما بچه ها
167
00:05:49,919 –> 00:05:52,080
ویدیوهای قبلی من را تماشا کرده اید، باید
168
00:05:52,080 –> 00:05:54,000
ایده ای داشته باشید که چگونه در um یک
169
00:05:54,000 –> 00:05:56,240
csv در اینجا بخوانید. نکته اما من دوست دارم به
170
00:05:56,240 –> 00:05:57,840
شما بچه ها نشان دهم که همه چیز در اینجا چه کاری
171
00:05:57,840 –> 00:06:00,319
انجام می دهد، بنابراین ما فقط
172
00:06:00,319 –> 00:06:03,840
یک لیست um خالی برای ذخیره داده های خود تعریف می
173
00:06:03,840 –> 00:06:05,600
کنیم و سپس فایل csv را باز می
174
00:06:05,600 –> 00:06:07,520
کنیم که به شما نشان دادم به نام
175
00:06:07,520 –> 00:06:09,520
csv فقط یک
176
00:06:09,520 –> 00:06:11,120
ستون داده وجود دارد، بنابراین در واقع هیچ
177
00:06:11,120 –> 00:06:13,520
کاما در این فایل وجود ندارد، اما اگر ما
178
00:06:13,520 –> 00:06:15,520
بیش از یک um
179
00:06:15,520 –> 00:06:17,360
بیشتر از یک ستون داده داشته باشیم،
180
00:06:17,360 –> 00:06:19,199
آنها را با کاما با uh از هم جدا می
181
00:06:19,199 –> 00:06:20,720
کنیم که به آن uh
182
00:06:20,720 –> 00:06:23,520
um yeah csv می گویند.
183
00:06:23,520 –> 00:06:25,600
اما اوه بله، هر ردیف در اینجا فقط
184
00:06:25,600 –> 00:06:26,479
یک
185
00:06:26,479 –> 00:06:27,520
نقطه داده
186
00:06:27,520 –> 00:06:29,600
و t است ما فقط میخواهیم
187
00:06:29,600 –> 00:06:32,800
خواننده csv خود را تعریف کنیم و سپس مجموعه دادههایمان را از
188
00:06:32,800 –> 00:06:35,360
طریق um تکرار کنیم
189
00:06:35,360 –> 00:06:38,720
و همه این um
190
00:06:38,720 –> 00:06:42,400
همه این نقاط داده را به لیست دادههای خود
191
00:06:42,400 –> 00:06:44,960
اضافه کنیم تا این لیست خالی را
192
00:06:44,960 –> 00:06:46,639
با um همه این دادهها پر کنیم. نقاط موجود در
193
00:06:46,639 –> 00:06:48,400
194
00:06:48,400 –> 00:06:51,440
فایل csv ما بسیار مهم است
195
00:06:51,440 –> 00:06:53,440
، مطمئن شوید که
196
00:06:53,440 –> 00:06:56,479
نقاط داده را در یک نوع عددی قرار می دهید،
197
00:06:56,479 –> 00:06:58,240
بنابراین باید آنها را در یک شناور قرار دهید یا واقعاً
198
00:06:58,240 –> 00:07:01,120
در این مورد می توانید آنها را
199
00:07:01,120 –> 00:07:03,199
به ins تبدیل کنید زیرا همه اینها
200
00:07:03,199 –> 00:07:05,599
اعداد صحیح هستند. اما من فقط گفتم float چون
201
00:07:05,599 –> 00:07:07,599
میخواهم آن را ثابت نگه دارم تا بتوانید
202
00:07:07,599 –> 00:07:09,680
همین کار را برای یک مجموعه داده پیوسته انجام دهید
203
00:07:09,680 –> 00:07:12,880
که همه فقط ins نبودند، اما در
204
00:07:12,880 –> 00:07:14,639
این مورد میتوانید آن را به
205
00:07:14,639 –> 00:07:16,720
ins ارسال کنید، اما من فقط میخواهم آنها را به صورت
206
00:07:16,720 –> 00:07:19,440
شناور نگه دارید فقط برای اینکه این um را
207
00:07:19,440 –> 00:07:22,080
نگه دارید این را نگه دارید تا بتوان آن را به
208
00:07:22,080 –> 00:07:24,800
انواع مختلف مجموعه داده تعمیم داد،
209
00:07:24,800 –> 00:07:27,759
خب پس حالا بیایید فقط داده هایمان را رسم کنیم
210
00:07:27,759 –> 00:07:30,240
و مطمئن شویم که آن را اشتباه خوانده ایم
211
00:07:30,240 –> 00:07:31,840
و یکسان به نظر می رسد به عنوان
212
00:07:31,840 –> 00:07:33,199
این طرح در
213
00:07:33,199 –> 00:07:35,039
اینجا، اوم
214
00:07:35,039 –> 00:07:37,120
بله، ما می خواهیم بگوییم plt
215
00:07:37,120 –> 00:07:39,680
dot h در اینجا یک هیستوگرام
216
00:07:39,680 –> 00:07:41,599
از دادههایمان دریافت میکنیم
217
00:07:41,599 –> 00:07:43,360
و سپس
218
00:07:43,360 –> 00:07:46,720
219
00:07:46,720 –> 00:07:48,720
bin
220
00:07:48,720 –> 00:07:51,120
ها با دادههای np.max um برابر است، بنابراین این فقط راهی برای گفتن است
221
00:07:51,120 –> 00:07:53,440
که میخواهیم به
222
00:07:53,440 –> 00:07:55,680
هر مقداری که بالاترین عدد در اینجا باشد، آن تعداد binها را
223
00:07:55,680 –> 00:07:58,319
میخواهیم تا داشته باشیم. یک
224
00:07:58,319 –> 00:07:59,199
بن
225
00:07:59,199 –> 00:08:02,720
ام ام به ازای هر تعداد مشتری ممکن است،
226
00:08:02,720 –> 00:08:04,479
مثلاً یک
227
00:08:04,479 –> 00:08:06,560
روش پیچیده برای گفتن آن و سپس
228
00:08:06,560 –> 00:08:08,240
229
00:08:08,240 –> 00:08:10,800
تراکم
230
00:08:11,199 –> 00:08:14,960
و سپس آلفا برابر با
231
00:08:14,960 –> 00:08:17,919
0.5 است که آنها آن را
232
00:08:17,919 –> 00:08:19,199
خوب می کنند، بعداً خواهید دید که چرا آن را داریم
233
00:08:19,199 –> 00:08:21,360
زیرا این فقط است. میلهها را
234
00:08:21,360 –> 00:08:23,599
تا حدی شفاف کنیم تا بتوانیم
235
00:08:23,599 –> 00:08:26,240
بعداً طرح دیگری را روی آن ترسیم کنیم
236
00:08:26,240 –> 00:08:28,560
و بتوانیم این طرح دیگر را ببینیم، اما
237
00:08:28,560 –> 00:08:30,479
بله، فعلاً به من در مورد آن یکی اعتماد کنید،
238
00:08:30,479 –> 00:08:31,759
اما
239
00:08:31,759 –> 00:08:34,399
بله خوب
240
00:08:34,479 –> 00:08:35,599
است، اجازه دهید ببینیم چه چیزی به دست میدهد.
241
00:08:35,599 –> 00:08:38,159
بیایید ببینیم که
242
00:08:38,159 –> 00:08:41,719
آیا دادهها را
243
00:08:42,958 –> 00:08:44,959
خواندهایم، بله، پس خوب به نظر میرسد که
244
00:08:44,959 –> 00:08:46,560
قرار است چگونه به نظر برسد، بنابراین به نظر میرسد
245
00:08:46,560 –> 00:08:48,560
که آن را به درستی مینویسیم و سپس دوباره
246
00:08:48,560 –> 00:08:49,920
اوم
247
00:08:49,920 –> 00:08:51,920
، فقط این را مانند چگالی تنظیم کردهایم
248
00:08:51,920 –> 00:08:54,640
درست باشد تا ما شاهد
249
00:08:54,640 –> 00:08:56,240
تعداد وقوع آن نباشیم دیگر ما در حال
250
00:08:56,240 –> 00:08:57,600
می بینیم ام
251
00:08:57,600 –> 00:08:58,959
، مانند
252
00:08:58,959 –> 00:09:01,920
احتمالات واقعی در محور uh y می
253
00:09:01,920 –> 00:09:03,839
بینیم، اما بله، منظورم این است که ما فقط می
254
00:09:03,839 –> 00:09:05,360
خواهیم بررسی کنیم و ببینیم که مطمئن شویم
255
00:09:05,360 –> 00:09:08,800
شکل کلی آن مشابه
256
00:09:08,800 –> 00:09:10,800
این طرح اصلی است،
257
00:09:10,800 –> 00:09:12,480
اما بله بنابراین خوب به نظر می رسد، بنابراین ما می توانیم
258
00:09:12,480 –> 00:09:14,959
ادامه دهیم،
259
00:09:14,959 –> 00:09:16,240
من فقط می خواهم در این مورد نظر بدهم،
260
00:09:16,240 –> 00:09:18,399
بنابراین کار بعدی که می
261
00:09:18,399 –> 00:09:20,240
خواهیم انجام دهیم این است که
262
00:09:20,240 –> 00:09:22,000
با تمام این ویدیوهای تخمین پارامتری
263
00:09:22,000 –> 00:09:24,320
که باید تعریف کنیم انجام داده ایم. برخی از
264
00:09:24,320 –> 00:09:26,800
تابع ضرر و تابع ضرر
265
00:09:26,800 –> 00:09:28,800
قرار است um
266
00:09:28,800 –> 00:09:30,640
باشد همان چیزی است که ما سعی خواهیم کرد آن
267
00:09:30,640 –> 00:09:32,720
را به حداقل برسانیم.
268
00:09:32,720 –> 00:09:34,399
269
00:09:34,399 –> 00:09:36,320
270
00:09:36,320 –> 00:09:38,399
این قبلاً با توزیع پواسون
271
00:09:38,399 –> 00:09:39,600
272
00:09:39,600 –> 00:09:41,120
مانند
273
00:09:41,120 –> 00:09:43,440
کیفیت خاصی
274
00:09:43,440 –> 00:09:45,440
دارد که فقط
275
00:09:45,440 –> 00:09:46,240
276
00:09:46,240 –> 00:09:48,560
یک پارامتر دارد و تنها
277
00:09:48,560 –> 00:09:51,760
پارامتر میانگین است و سپس واریانس um در
278
00:09:51,760 –> 00:09:54,240
واقع برابر با میانگین است بنابراین در
279
00:09:54,240 –> 00:09:56,080
مورد خاص توزیع پواسون
280
00:09:56,080 –> 00:09:58,320
در واقع ساده ترین راه است. متناسب با
281
00:09:58,320 –> 00:10:00,720
منطقه ibution برای داده های شما این است که
282
00:10:00,720 –> 00:10:02,720
فقط میانگین داده های خود را بگیرید و سپس
283
00:10:02,720 –> 00:10:04,959
این تنها پارامتری است که
284
00:10:04,959 –> 00:10:07,440
برای توزیع پواسون um به
285
00:10:07,440 –> 00:10:09,440
آن نیاز دارید زیرا فقط um را می گیرد و فقط پارامتر میانگین را می گیرد
286
00:10:09,440 –> 00:10:10,800
و سپس واریانس
287
00:10:10,800 –> 00:10:12,079
برابر با میانگین است
288
00:10:12,079 –> 00:10:13,839
اما این مانند کیفیت خاصی از
289
00:10:13,839 –> 00:10:15,519
توزیع پواسون که در مورد توزیعهای دیگر صدق نمیکند،
290
00:10:15,519 –> 00:10:17,279
بنابراین حتی اگر
291
00:10:17,279 –> 00:10:19,440
این راه آسان برای تطبیق توزیع پواسون
292
00:10:19,440 –> 00:10:21,200
با دادهها این است که فقط
293
00:10:21,200 –> 00:10:22,560
میانگین دادهها را در نظر بگیرید و این تنها
294
00:10:22,560 –> 00:10:24,000
پارامتری است که نیاز دارید،
295
00:10:24,000 –> 00:10:26,640
من میخواهم به شما نشان دهم. بچه ها روشی برای
296
00:10:26,640 –> 00:10:29,120
تناسب توزیعی که می تواند
297
00:10:29,120 –> 00:10:31,680
به سایر توزیع های گسسته تعمیم داده شود، بنابراین
298
00:10:31,680 –> 00:10:33,519
حتی اگر poisson
299
00:10:33,519 –> 00:10:35,760
um این راه آسان را برای انجام آن دارد،
300
00:10:35,760 –> 00:10:37,760
من یک راه کمی سخت تر را به شما دوستان نشان خواهم داد
301
00:10:37,760 –> 00:10:39,839
که می تواند به um های دیگر تعمیم داده شود.
302
00:10:39,839 –> 00:10:41,920
انواع توزیعهای گسسته، اما
303
00:10:41,920 –> 00:10:43,600
بله، همانطور که قبلاً گفتم
304
00:10:43,600 –> 00:10:44,839
305
00:10:44,839 –> 00:10:46,880
306
00:10:46,880 –> 00:10:48,560
307
00:10:48,560 –> 00:10:50,880
308
00:10:50,880 –> 00:10:54,160
. مدل ur از دادهها است
309
00:10:54,160 –> 00:10:56,160
و پس از اینکه تابع ضرر
310
00:10:56,160 –> 00:10:58,240
را نوشتیم، تنها کاری که باید انجام دهیم این
311
00:10:58,240 –> 00:11:01,440
است که مقادیر پارامتری را پیدا
312
00:11:01,440 –> 00:11:03,120
کنیم که تابع ضرر
313
00:11:03,120 –> 00:11:04,640
را به حداقل میرساند، زیرا فاصله مدل ما از um را به حداقل میرساند.
314
00:11:04,640 –> 00:11:07,519
315
00:11:07,519 –> 00:11:08,399
316
00:11:08,399 –> 00:11:10,240
دادهها، بله، مشکل با همه اینها این
317
00:11:10,240 –> 00:11:11,839
است که فقط یک تابع از دست دادن بنویسید و
318
00:11:11,839 –> 00:11:13,920
سپس میتوانید به راحتی
319
00:11:13,920 –> 00:11:16,560
پیدا کنید که چه مقدار پارامتری آن را به حداقل
320
00:11:16,560 –> 00:11:17,940
میرساند، بنابراین بله، ما از اینجا شروع میکنیم
321
00:11:17,940 –> 00:11:19,200
[Music]
322
00:11:19,200 –> 00:11:19,800
،
323
00:11:19,800 –> 00:11:20,959
324
00:11:20,959 –> 00:11:22,560
تابع از دست دادن [
325
00:11:22,560 –> 00:11:24,320
Music] را
326
00:11:24,320 –> 00:11:26,079
همانطور که گفتم تعریف
327
00:11:26,079 –> 00:11:29,040
میکنیم. فقط