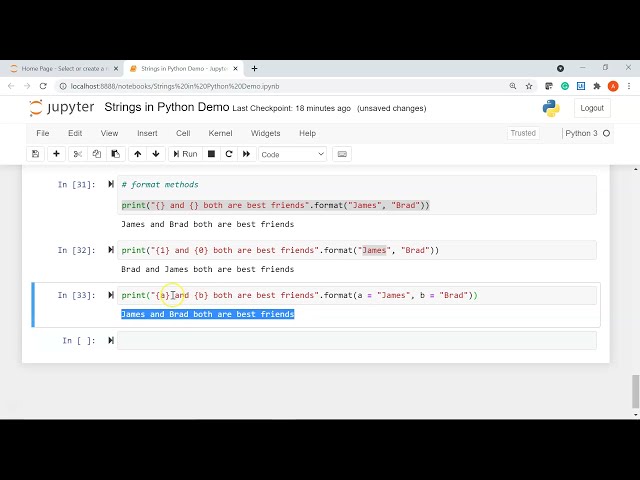
در این مطلب، ویدئو دوره سقوط پانداها در 1 ساعت | آموزش پایتون پانداها | آموزش پانداها – دوره کامل| تاکی KGP با زیرنویس فارسی را برای دانلود قرار داده ام. شما میتوانید با پرداخت 15 هزار تومان ، این ویدیو به علاوه تمامی فیلم های سایت را دانلود کنید.اکثر فیلم های سایت به زبان انگلیسی می باشند. این ویدئو دارای زیرنویس فارسی ترجمه شده توسط هوش مصنوعی می باشد که میتوانید نمونه ای از آن را در قسمت پایانی این مطلب مشاهده کنید.
مدت زمان فیلم: 1:12:11
تصاویر این ویدئو:




قسمتی از زیرنویس این فیلم:
00:00:00,439 –> 00:00:03,480
سلام خوش آمدید به شما خوش آمدید بدانید گوش کنید
2
00:00:03,480 –> 00:00:05,970
این اجازه دهید من را ببینم نمی توانم نگران نباشم در این درس
3
00:00:05,970 –> 00:00:08,309
من شما را با
4
00:00:08,309 –> 00:00:10,980
دوره خرابی ضمیمه آشنا خواهم کرد و اگر در مورد پایتون نمی دانید ابتدا
5
00:00:10,980 –> 00:00:14,910
به شما پیشنهاد می کنم که آموزش دوره خرابی
6
00:00:14,910 –> 00:00:17,690
7
00:00:17,690 –> 00:00:20,939
پایتون را بخوانید. یادگیری قلم بسیار آسان خواهد بود
8
00:00:20,939 –> 00:00:24,859
– اگر ابتدا
9
00:00:24,859 –> 00:00:28,080
بسته پایتون 2 را مرور کنید مهم ترین
10
00:00:28,080 –> 00:00:29,519
ابزاری است که در اختیار دانشمندان داده
11
00:00:29,519 –> 00:00:31,740
و تحلیلگری است که
12
00:00:31,740 –> 00:00:33,960
امروزه در پایتون کار می کند، یادگیری ماشین قدرتمند
13
00:00:33,960 –> 00:00:35,790
و ابزار تجسم پر زرق و برق
14
00:00:35,790 –> 00:00:38,309
ممکن است همه چیز را دریافت کند. توجه داشته باشید، اما
15
00:00:38,309 –> 00:00:38,910
16
00:00:38,910 –> 00:00:40,760
PennDOT ستون فقرات بسیاری از پروژه های داده است،
17
00:00:40,760 –> 00:00:43,860
اگر به
18
00:00:43,860 –> 00:00:45,750
علم داده به عنوان یک حامل فکر می کنید، پس
19
00:00:45,750 –> 00:00:47,520
ضروری است که یکی از اولین کارهایی
20
00:00:47,520 –> 00:00:50,520
که انجام می دهید پانداهای کوچک در این
21
00:00:50,520 –> 00:00:53,070
مجموعه ویدیویی است که ما موارد ضروری را مرور خواهیم کرد.
22
00:00:53,070 –> 00:00:55,050
اطلاعاتی در مورد پانداها،
23
00:00:55,050 –> 00:00:58,230
از جمله نحوه نصب آن، نحوه استفاده از
24
00:00:58,230 –> 00:01:00,809
آن، نحوه کار با سایر بسته های رایج
25
00:01:00,809 –> 00:01:02,789
تجزیه و تحلیل داده پایتون مانند matplotlib
26
00:01:02,789 –> 00:01:05,600
و scikit-learn،
27
00:01:05,600 –> 00:01:08,189
اما قبل از استفاده از th و پانداها باید
28
00:01:08,189 –> 00:01:10,020
تواناییهای
29
00:01:10,020 –> 00:01:13,290
پانداها را درک کنیم که چه کاری میتواند انجام دهد.
30
00:01:13,290 –> 00:01:17,040
31
00:01:17,040 –> 00:01:20,220
32
00:01:20,220 –> 00:01:23,280
33
00:01:23,280 –> 00:01:26,100
فایل
34
00:01:26,100 –> 00:01:28,619
در قالب فایل JSON یا
35
00:01:28,619 –> 00:01:32,670
هر نوع فایل داده دیگری مانند شما
36
00:01:32,670 –> 00:01:35,040
می توانید تجزیه و تحلیل آماری مانند
37
00:01:35,040 –> 00:01:37,710
محاسبه میانگین میانگین حداکثر میانگین
38
00:01:37,710 –> 00:01:40,560
ردیف های ما را انجام دهید، می توانید
39
00:01:40,560 –> 00:01:42,540
همبستگی بین ستون ها و
40
00:01:42,540 –> 00:01:45,180
ردیف ها را انجام دهید که می توانید بفهمید.
41
00:01:45,180 –> 00:01:49,020
توزیع داده ها در یک ستون و ردیف شما می
42
00:01:49,020 –> 00:01:52,229
توانید پاکسازی فایل های داده خود را مانند
43
00:01:52,229 –> 00:01:54,920
حذف مقادیر از دست رفته،
44
00:01:54,920 –> 00:01:57,329
فیلتر کردن ردیف های پرت و ستون را با
45
00:01:57,329 –> 00:02:00,450
معیارهایی مانند اعمال
46
00:02:00,450 –> 00:02:03,360
یک تابع منطقی یا ریاضی انجام دهید و در نهایت
47
00:02:03,360 –> 00:02:05,280
می توانید تجسم داده ها را
48
00:02:05,280 –> 00:02:07,950
با کمک از کتابخانه مات پلات با استفاده از
49
00:02:07,950 –> 00:02:12,800
میلههای طرح میلههای خط، تاریخچه طرح خط،
50
00:02:12,800 –> 00:02:16,370
نمودار حبابدار و انواع دیگر
51
00:02:16,370 –> 00:02:20,300
نمودارها و سپس در نهایت هنگامی
52
00:02:20,300 –> 00:02:23,960
که دادههای تمیز خود را به دست آوردید. میتوانید
53
00:02:23,960 –> 00:02:26,570
این دادهها را تبدیل کنید و در نهایت
54
00:02:26,570 –> 00:02:30,440
میتوانید دوباره در یک فایل CSV بنویسید، در چند سال
55
00:02:30,440 –> 00:02:32,660
گذشته محبوبیتی برای پانداها افزایش یافته است،
56
00:02:32,660 –> 00:02:35,270
بهویژه در شش
57
00:02:35,270 –> 00:02:36,200
تا هفت سال گذشته،
58
00:02:36,200 –> 00:02:39,440
محبوبیت پانداها به طور
59
00:02:39,440 –> 00:02:41,450
تصاعدی در میان
60
00:02:41,450 –> 00:02:44,750
دانشمندان داده و این پانداها افزایش یافته است.
61
00:02:44,750 –> 00:02:47,930
تقریباً اولین انتخاب در بین
62
00:02:47,930 –> 00:02:50,090
دانشمندان داده و یادگیری ماشینی
63
00:02:50,090 –> 00:02:53,450
از طریق جوی استیک بوده است،
64
00:02:53,450 –> 00:02:55,910
خوب، پانداها در بالای بسته بیحرکت ساخته شدهاند، به این
65
00:02:55,910 –> 00:02:59,180
معنی که
66
00:02:59,180 –> 00:03:02,570
ساختاری از
67
00:03:02,570 –> 00:03:05,750
68
00:03:05,750 –> 00:03:08,720
پاندا است. اغلب برای تغذیه
69
00:03:08,720 –> 00:03:11,270
تجزیه و تحلیل آماری به آه با رسم
70
00:03:11,270 –> 00:03:13,340
تابع از لبه نمودار ارتفاع و
71
00:03:13,340 –> 00:03:15,050
الگوریتم یادگیری ماشین در
72
00:03:15,050 –> 00:03:18,320
scikit-learn استفاده می شود، به این معنی که اگر پانداها را می شناسید،
73
00:03:18,320 –> 00:03:21,350
این به شما در
74
00:03:21,350 –> 00:03:24,290
یادگیری یادگیری ماشینی یادگیری ماشینی کمک می کند که
75
00:03:24,290 –> 00:03:26,230
اساسا ما از هر دو استفاده می کنیم.
76
00:03:26,230 –> 00:03:31,340
Kira با قسمت پشتی
77
00:03:31,340 –> 00:03:34,400
تنسورفلو، ما یادگیری بسیار بزرگی از Sicit داریم، بنابراین بهویژه از
78
00:03:34,400 –> 00:03:37,730
Sicit-Lear برای
79
00:03:37,730 –> 00:03:39,530
یادگیری ماشین کلاسیک و برای یادگیری عمیق استفاده میکنیم. یادگیری
80
00:03:39,530 –> 00:03:45,500
ما از tensorflow استفاده میکنیم و میتوانیم این
81
00:03:45,500 –> 00:03:48,980
برنامهنویسی را در بسیاری
82
00:03:48,980 –> 00:03:49,970
از ایدههای دیگر مانند
83
00:03:49,970 –> 00:03:56,240
pycharm و آیتم متنی عالی یا نوتبوک مشتری انجام
84
00:03:56,240 –> 00:04:00,140
دهیم، استودیوی تصویری ما را خوب میکند، بنابراین
85
00:04:00,140 –> 00:04:02,720
در اینجا در این مجموعه ویدیویی،
86
00:04:02,720 –> 00:04:05,680
ما با نوتبوک مشتری و
87
00:04:05,680 –> 00:04:07,760
نوتبوک مشتری کار خوبی ارائه میدهیم.
88
00:04:07,760 –> 00:04:10,010
محیطی برای استفاده از پانداها برای انجام کاوش داده ها
89
00:04:10,010 –> 00:04:14,090
و مدل سازی و ما می
90
00:04:14,090 –> 00:04:16,220
توانیم این نوت بوک مشتری را با آناکوندای خود دانلود کنیم،
91
00:04:16,220 –> 00:04:19,459
باید به آناکوندا
92
00:04:19,459 –> 00:04:23,060
آرام بروید و سپس نسخه 3.7 پایتون را دانلود کنید
93
00:04:23,060 –> 00:04:26,690
چون من یک آیه پایتون 3.7
94
00:04:26,690 –> 00:04:28,640
دارم به شما پیشنهاد می کنم پایتون را هم دانلود کنید.
95
00:04:28,640 –> 00:04:31,580
نسخه 3.7 من قبلاً
96
00:04:31,580 –> 00:04:33,320
این آناکوندا را دانلود کردهام و
97
00:04:33,320 –> 00:04:35,720
قبلاً آن را نصب کردهام، بنابراین هنگامی
98
00:04:35,720 –> 00:04:37,910
که آناکوندا را
99
00:04:37,910 –> 00:04:39,950
نصب کردید، نوتبوک مشتری و
100
00:04:39,950 –> 00:04:43,100
اکثر کتابخانههای پایتون را بهطور
101
00:04:43,100 –> 00:04:47,080
خودکار مانند قلم داور – علمی تخیلی و انواع دیگر
102
00:04:47,080 –> 00:04:50,780
کتابخانههای پایتون که در به طور کلی
103
00:04:50,780 –> 00:04:54,020
در تکنیک های یادگیری ماشینی و تجزیه و تحلیل داده ما
104
00:04:54,020 –> 00:05:01,130
خوب است،
105
00:05:01,130 –> 00:05:04,610
بنابراین اجازه دهید به شما نشان دهم چگونه می توانید این کار را انجام دهید،
106
00:05:04,610 –> 00:05:06,830
بنابراین باید اینجا تایپ کنید آناکوندا
107
00:05:06,830 –> 00:05:09,560
و سپس من به شما پیشنهاد می کنم آن را
108
00:05:09,560 –> 00:05:12,770
به عنوان یک مدیر راه اندازی کنید، بنابراین هنگامی که آن را
109
00:05:12,770 –> 00:05:13,850
به عنوان مدیر راه اندازی
110
00:05:13,850 –> 00:05:17,140
کردید، در فهرست ویندوز system32 باز می
111
00:05:17,140 –> 00:05:20,600
شود، سپس باید آن را به
112
00:05:20,600 –> 00:05:23,950
جایی که می خواهید فایل های برنامه نویسی خود را ذخیره کنید هدایت کنید،
113
00:05:23,950 –> 00:05:27,080
بنابراین من در اینجا
114
00:05:27,080 –> 00:05:32,060
یک فایل جدید ایجاد کردم. دایرکتوری که دوره سقوط پانداها است،
115
00:05:32,060 –> 00:05:34,220
بنابراین من می خواهم
116
00:05:34,220 –> 00:05:37,040
دایرکتوری کاری خود را در آنجا تغییر دهم، زمانی که دایرکتوری کاری خود را در
117
00:05:37,040 –> 00:05:38,960
آنجا تغییر دادم، سپس
118
00:05:38,960 –> 00:05:41,510
باید اینجا بنویسم Jupiter notebook
119
00:05:41,510 –> 00:05:48,169
بسیار خوب است، بنابراین وقتی یک نوت بوک Jupiter داشته باشم،
120
00:05:48,169 –> 00:05:51,230
یک سرور محلی
121
00:05:51,230 –> 00:05:54,169
روی من اجرا می کند. کامپیوتر و در نهایت
122
00:05:54,169 –> 00:05:56,810
یک سرور محلی را در مرورگر وب ترجیحی من
123
00:05:56,810 –> 00:05:59,900
باز می کند، در این مورد گوگل
124
00:05:59,900 –> 00:06:06,110
کروم است، در نهایت وقتی این
125
00:06:06,110 –> 00:06:08,120
نوت بوک Jupiter را باز کردید، می توانید
126
00:06:08,120 –> 00:06:10,600
اینجا ایجاد کنید یا می توانید
127
00:06:10,600 –> 00:06:14,870
فایل های جدید را در اینجا آپلود کنید، می توانید یک فایل جدید ایجاد کنید.
128
00:06:14,870 –> 00:06:17,510
در اینجا اجازه دهید یک فایل جدید ایجاد کنیم و سپس
129
00:06:17,510 –> 00:06:22,010
نام آن را به عنوان یک قلم تغییر میدهم.
130
00:06:22,010 –> 00:06:30,350
131
00:06:30,350 –> 00:06:33,110
132
00:06:33,110 –> 00:06:35,720
لبه صفحه کلید با
133
00:06:35,720 –> 00:06:38,479
فشار دادن H یک میانبر صفحه کلید باز می شود
134
00:06:38,479 –> 00:06:40,940
و در اینجا می بینید
135
00:06:40,940 –> 00:06:45,860
که اگر جایگزین را پیدا می کند و pH
136
00:06:45,860 –> 00:06:48,920
پالت فرمان را باز می کند که چرا سلول را
137
00:06:48,920 –> 00:06:49,520
138
00:06:49,520 –> 00:06:54,560
به cult MH تغییر دهید تا سلول را به علامت گذاری و یکی را
139
00:06:54,560 –> 00:06:57,140
با سلول تغییر به عنوان یک
140
00:06:57,140 –> 00:06:59,210
و دو تغییر دهید. برای عنوان دو سه چهار
141
00:06:59,210 –> 00:07:01,010
سرفصل سه و چهار برای سرفصل چهار
142
00:07:01,010 –> 00:07:03,920
و غیره به سمت راست، بنابراین اساساً
143
00:07:03,920 –> 00:07:07,400
من بیشتر از درج یک سلول در بالا
144
00:07:07,400 –> 00:07:10,790
و B درج یک سلول در زیر و X برای
145
00:07:10,790 –> 00:07:13,370
برش سلول و C برای کپی سلول و V
146
00:07:13,370 –> 00:07:16,880
برای سلول را ماهیگیری کنید و بررسی کنید تا انتخاب را لغو
147
00:07:16,880 –> 00:07:21,320
کنید بسیار عالی است،
148
00:07:21,320 –> 00:07:24,440
بنابراین بهترین راه برای شروع پایتون چیست،
149
00:07:24,440 –> 00:07:28,190
اگر پانداها را ندارید، برنامه نویسی ضمیمه را شروع کنید،
150
00:07:28,190 –> 00:07:30,050
سپس می
151
00:07:30,050 –> 00:07:32,300
توانید آن را با کد نصب نصب کنید.
152
00:07:32,300 –> 00:07:35,390
153
00:07:35,390 –> 00:07:38,210
قبلاً آن را از طریق آناکوندا نصب کردهاید
154
00:07:38,210 –> 00:07:40,250
و البته وقتی
155
00:07:40,250 –> 00:07:42,320
آناکوندای خود را نصب کردید، پانداها به
156
00:07:42,320 –> 00:07:44,690
طور خودکار روی
157
00:07:44,690 –> 00:07:48,830
رایانه شما نصب میشوند، بنابراین بیایید کدگذاری پانداهایمان را شروع کنیم،
158
00:07:48,830 –> 00:07:52,040
بنابراین ابتدا باید بستههای فروشندگان خود را وارد کنید.
159
00:07:52,040 –> 00:07:56,510
ge را در نوت بوک مشتری خود قرار دهید
160
00:07:56,510 –> 00:08:01,100
و می توانید این کار را با Import bandage
161
00:08:01,100 –> 00:08:04,460
به عنوان PD انجام دهید این روش ترجیح داده شده است و برای
162
00:08:04,460 –> 00:08:08,210
اجرای این سلول می توانید این کار را به
163
00:08:08,210 –> 00:08:10,940
سه طریق انجام دهید ابتدا Shift + Enter
164
00:08:10,940 –> 00:08:13,910
اگر من الک کنم و وارد کنم می بینید اینجا
165
00:08:13,910 –> 00:08:17,090
یک وجود دارد علامت ستاره و آن علامت ستاره
166
00:08:17,090 –> 00:08:19,340
می گوید که این سلول در حال اجرا است
167
00:08:19,340 –> 00:08:23,180
و سرور برای اجرای یک سلول دیگر در دسترس نیست،
168
00:08:23,180 –> 00:08:26,419
درست است چون
169
00:08:26,419 –> 00:08:27,860
Shift + Enter را فشار داده بودم،
170
00:08:27,860 –> 00:08:31,250
بنابراین این سلول اجرا شد و سلول جدید
171
00:08:31,250 –> 00:08:35,690
ایجاد شد و فرض کنید اگر این سلول را برش دادم
172
00:08:35,690 –> 00:08:39,860
فقط X را فشار دهید، بنابراین اگر X را فشار دهم،
173
00:08:39,860 –> 00:08:44,179
این سلول قطع می شود و اگر
174
00:08:44,179 –> 00:08:46,820
این را با ctrl + Enter
175
00:08:46,820 –> 00:08:50,780
اجرا کنم، در اینجا خواهید دید که این سلول را اجرا می
176
00:08:50,780 –> 00:08:53,300
کند اما وارد فروش جدید نمی شود،
177
00:08:53,300 –> 00:08:54,020
178
00:08:54,020 –> 00:08:57,050
بنابراین ترجیح داده شده
179
00:08:57,050 –> 00:08:59,810
است. با Shift + Enter خیلی
180
00:08:59,810 –> 00:09:05,210
خوب است، بنابراین
181
00:09:05,210 –> 00:09:08,030
اگر در اینجا PD و یک نقطه بنویسیم، آویزهای خود را به شکل PD داریم
182
00:09:08,030 –> 00:09:11,540
و
183
00:09:11,540 –> 00:09:13,970
اگر یک برگه را فشار دهیم فقط زمان را فشار دهیم، در اینجا خواهید
184
00:09:13,970 –> 00:09:16,790
دید که بله یک دایره پر از دایره وجود دارد
185
00:09:16,790 –> 00:09:19,610
که قبلاً انجام شده است. هسته VG است خوب
186
00:09:19,610 –> 00:09:21,710
هسته VG است و هسته در حال نمایهسازی است
187
00:09:21,710 –> 00:09:23,180
و فهمیدن این پیشنهادات
188
00:09:23,180 –> 00:09:25,820
چه چیزهای دیگری هستند که میتوانیم
189
00:09:25,820 –> 00:09:28,850
روی نقطه PD اعمال کنیم، یعنی
190
00:09:28,850 –> 00:09:30,410
اینها کارهایی هستند که میتوانیم انجام دهیم
191
00:09:30,410 –> 00:09:34,120
مانند آرایه P dot API ترتیب
192
00:09:34,120 –> 00:09:37,100
پذیرنده هسته Concord جمعوجور دستهبندی،
193
00:09:37,100 –> 00:09:39,740
دادههای چیزهای زیادی وجود دارد. خطای
194
00:09:39,740 –> 00:09:40,670
زمان تغییر تاریخ فریم داده
195
00:09:40,670 –> 00:09:43,640
به جز سعی کنید بپذیرید همه این کارها را
196
00:09:43,640 –> 00:09:47,360
می توان به درستی انجام داد، مانند خواندن
197
00:09:47,360 –> 00:09:50,930
وضعیت خواندن SQL رتبه داده های ما JSON HTML
198
00:09:50,930 –> 00:09:53,720
درست است، بنابراین این نوع چیزها را می توان در
199
00:09:53,720 –> 00:09:56,960
این زمان خواند، انباشته ها را می توان
200
00:09:56,960 –> 00:09:59,480
در تاریخ نوشت/ زمان CSV به جز
201
00:09:59,480 –> 00:10:04,040
ردیابی cetera خوب است، بنابراین اجزای اصلی پانداها چیست، آن
202
00:10:04,040 –> 00:10:06,410
203
00:10:06,410 –> 00:10:10,070
اجزای اصلی سری API هستند، درست در اینجا
204
00:10:10,070 –> 00:10:12,290
این سری یک سری وجود دارد
205
00:10:12,290 –> 00:10:16,010
و قاب داده خوب است، بنابراین
206
00:10:16,010 –> 00:10:18,590
این دو مؤلفه اصلی هستند، بنابراین ما
207
00:10:18,590 –> 00:10:22,750
می توانیم انجام دهیم با نظر اینجا سری و
208
00:10:22,750 –> 00:10:26,390
قاب داده، بنابراین اینها اجزای اصلی
209
00:10:26,390 –> 00:10:30,770
یک پاندا هستند، بنابراین ما می
210
00:10:30,770 –> 00:10:33,980
توانیم سری و پانداها را ایجاد کنیم، بنابراین چگونه
211
00:10:33,980 –> 00:10:37,850
می توانیم ساده ترین راه را برای ایجاد یک
212
00:10:37,850 –> 00:10:40,610
داده fr انجام دهیم. ame یا یک سری از ابتدا
213
00:10:40,610 –> 00:10:44,600
به پانداها فقط با استفاده از یک فرهنگ لغت
214
00:10:44,600 –> 00:10:46,910
در پایتون، بنابراین اجازه دهید یک
215
00:10:46,910 –> 00:10:49,760
فرهنگ لغت در اینجا ایجاد کنیم، اگر
216
00:10:49,760 –> 00:10:52,160
کدنویسی پایتون را به خاطر دارید، ما سه
217
00:10:52,160 –> 00:10:55,310
نوع از براکت داریم که اولی یک
218
00:10:55,310 –> 00:10:56,900
براکت فرفری است و سپس وجود دارد. یک
219
00:10:56,900 –> 00:10:59,000
پرانتز است و سپس یک براکت مربع وجود دارد،
220
00:10:59,000 –> 00:11:02,210
سپس رکورد فرفری نشان می دهد که
221
00:11:02,210 –> 00:11:04,760
فرهنگ لغت اکنون ما اینجا براکت فرفری داریم
222
00:11:04,760 –> 00:11:07,760
و در براکت فرفری به
223
00:11:07,760 –> 00:11:10,790
یک کلید و مقدار آن کلید نیاز داریم، بنابراین بیایید
224
00:11:10,790 –> 00:11:14,899
اینجا بگوییم من یک کلید اول مانند یک کلید دارم. رفیق
225
00:11:14,899 –> 00:11:19,370
باشه پس این کلید است و
226
00:11:19,370 –> 00:11:24,370
من چند نفر دارم بیایید بگوییم 3 1 2
227
00:11:24,370 –> 00:11:27,350
4 و 5 خوب است
228
00:11:27,350 –> 00:11:31,839
و سپس یکی دیگر من نارنجی دارم بیایید بگوییم
229
00:11:31,839 –> 00:11:38,690
خوب است بنابراین در نارنجی نارنجی کلید است و در
230
00:11:38,690 –> 00:11:41,180
این کلید نارنجی ما یک مقدار داریم
231
00:11:41,180 –> 00:11:43,639
این لیست مقدار است و در اینجا من یک
232
00:11:43,639 –> 00:11:47,480
1 و سپس 5 دارم و سپس یک 6 دارم و
233
00:11:47,480 –> 00:11:49,100
فرض کنید پس من یک 8
234
00:11:49,100 –> 00:11:52,910
ok دارم، بنابراین فقط کافی است روی Enter که
235
00:11:52,910 –> 00:11:55,220
از این اجرا دارم غربال کنید و بیایید این
236
00:11:55,220 –> 00:11:58,610
داده ای را که دارم اینجا چاپ کنیم. داده که
237
00:11:58,610 –> 00:12:03,380
سیب و پرتقال است و اگر چاپ کنم
238
00:12:03,380 –> 00:12:06,199
نوع این دا تا پس از آن یک نوع دیکشنری مناسب دریافت خواهید کرد،
239
00:12:06,199 –> 00:12:10,940
بنابراین وقتی
240
00:12:10,940 –> 00:12:13,819
این را دارید، پس آنچه می توانیم انجام دهیم، می
241
00:12:13,819 –> 00:12:19,430
توانیم قاب داده را با این ایجاد کنیم، بنابراین چگونه
242
00:12:19,430 –> 00:12:22,339
می توانیم انجام دهیم، فقط می توانیم اینجا بنویسیم که داده
243
00:12:22,339 –> 00:12:24,920
ها قاب داده مانند DF برابر است
244
00:12:24,920 –> 00:12:30,230
با قاب داده BD dot و سپس من می توانم
245
00:12:30,230 –> 00:12:33,260
این داده ها را ارسال کنم، سپس می توانیم این را اجرا کنیم و
246
00:12:33,260 –> 00:12:36,019
در نهایت می توانیم این PDF را چاپ کنیم، اکنون
247
00:12:36,019 –> 00:12:38,899
می بینید که اینجا این شاخص است
248
00:12:38,899 –> 00:12:41,930
و اینجا ما apple داریم و اینجا یک نارنجی داریم
249
00:12:41,930 –> 00:12:43,190
کاملاً درست است
250
00:12:43,190 –> 00:12:45,319
و قبلاً صحبت کردم. در مورد
251
00:12:45,319 –> 00:12:48,019
سری، بنابراین اگر فقط یک
252
00:12:48,019 –> 00:12:51,769
ستون وجود داشته باشد، یک سری خواهد بود، به این معنی
253
00:12:51,769 –> 00:12:56,180
که می توانیم آن را با استفاده از این روش چاپ کنیم، اگر
254
00:12:56,180 –> 00:13:00,199
من اینجا DF و apple را تایپ کنم، خواهید
255
00:13:00,199 –> 00:13:03,680
دید که این یک سری است چگونه می توانیم بفهمیم که
256
00:13:03,680 –> 00:13:05,600
این یک سری است. ما می توانیم در اینجا یک
257
00:13:05,600 –> 00:13:11,930
نوع و DF بنویسیم و سپس یک pal okay می بینید که
258
00:13:11,930 –> 00:13:15,380
این یک سری Okay است، به این معنی که اگر at
259
00:13:15,380 –> 00:13:17,839
اگر دو ستون یا بیشتر از
260
00:13:17,839 –> 00:13:20,449
دو ستون داشته باشد، همیشه یک قاب داده خواهد بود
261
00:13:20,449 –> 00:13:21,570
262
00:13:21,570 –> 00:13:24,389
اما اگر یک ستون داشته باشد. پس
263
00:13:24,389 –> 00:13:29,430
میتواند یک قاب داده یا یک سری باشد، حالا
264
00:13:29,430 –> 00:13:33,389
بیایید کار روی برخی دادههای واقعی را شروع کنیم
265
00:13:33,389 –> 00:13:38,790
y بنابراین چگونه میتوانیم یک داده واقعی انجام دهیم، میتوانیم
266
00:13:38,790 –> 00:13:41,790
یک داده واقعی دانلود کنیم، میتوانید یک
267
00:13:41,790 –> 00:13:44,399
داده واقعی را از مخزن github من دانلود کنید،
268
00:13:44,399 –> 00:13:46,920
میتوانید از اینجا بازدید کنید github.com به شما امکان میدهد
269
00:13:46,920 –> 00:13:53,310
فایلهای داده ایمیل آن را ایمیل کنید سپس میتوانید
270
00:13:53,310 –> 00:13:56,819
این فایلهای داده ایمیل را کپی کنید ml فایل های داده بسیار
271
00:13:56,819 –> 00:13:59,759
خوب، شما باید یا می توانید
272
00:13:59,759 –> 00:14:03,569
آن را در یک فایل فشرده دانلود کنید اگر قبلاً یک
273
00:14:03,569 –> 00:14:05,850
git در رایانه خود نصب کرده اید، سپس
274
00:14:05,850 –> 00:14:11,519
می توانید آن را شبیه سازی کنید، اگر آن را نصب
275
00:14:11,519 –> 00:14:14,310
کرده اید یا آن را دانلود کرده اید، بیایید
276
00:14:14,310 –> 00:14:20,190
این فایل داده را استخراج کنیم اکنون ما این را داریم
277
00:14:20,190 –> 00:14:23,699
فایل داده بیایید فقط این را کپی کنیم،
278
00:14:23,699 –> 00:14:26,250
می خواهیم آن را کپی کنیم و
279
00:14:26,250 –> 00:14:29,069
می خواهیم آن را در فهرست کار خود
280
00:14:29,069 –> 00:14:32,639
در اینجا در دوره تصادف دو پاندا جایگذاری کنیم، همین حالا
281
00:14:32,639 –> 00:14:36,000
وارد دوره سقوط پانداهایمان شده ایم.
282
00:14:36,000 –> 00:14:44,370
283
00:14:44,370 –> 00:14:49,740
می خواهم به شما بگویم چگونه
284
00:14:49,740 –> 00:14:57,569
فایل CSV را بخوانید درست است، بنابراین بیایید
285
00:14:57,569 –> 00:15:03,209
ابتدا چند ستون را معرفی کنیم تا بتوانیم
286
00:15:03,209 –> 00:15:06,029
در اینجا خیلی راحت کار کنیم، شما فقط می توانید
287
00:15:06,029 –> 00:15:09,769
B را فشار دهید تا مقدار زیادی از روچ
288
00:15:09,769 –> 00:15:15,930
پشت روچ کار
289
00:15:15,930 –> 00:15:19,829
شما وارد شود. رفتن به خواندن فایل CSV را
290
00:15:19,829 –> 00:15:22,230
در یک قاب داده قرار می دهیم، بنابراین ما می خواهیم
291
00:15:22,230 –> 00:15:25,319
آن را در قاب داده بخوانیم DF PD
292
00:15:25,319 –> 00:15:28,230
dot read زمانی که در اینجا بنویسیم خواندن و
293
00:15:28,230 –> 00:15:30,870
یک برگه را فشار دهیم، به طور خودکار به
294
00:15:30,870 –> 00:15:32,850
شما نشان می دهد که چه نوع هایی را می بینیم
295
00:15:32,850 –> 00:15:35,190
که قرار است بخواند. ببینید
296
00:15:35,190 –> 00:15:38,370
که ما اکسل داریم یا fwf یا چه نوع
297
00:15:38,370 –> 00:15:42,840
شمعی داریم، بنابراین در اینجا ما یک فایل CSV
298
00:15:42,840 –> 00:15:45,720
داریم، بنابراین میخواهیم یک فایل CSV را اینجا بخوانیم، بسیار
299
00:15:45,720 –> 00:15:48,870
خوب، پس وقتی فایل CSV داریم، اکنون
300
00:15:48,870 –> 00:15:50,640
باید نام فایلها را در اینجا ذکر کنیم،
301
00:15:50,640 –> 00:15:53,670
خب اجازه دهید بگویید اینجا
302
00:15:53,670 –> 00:15:55,530
تعداد زیادی نام از انبوهی داریم که قرار است
303
00:15:55,530 –> 00:15:58,710
ابتدا در نزدیکی NBA در تیم فوتبال بیج
304
00:15:58,710 –> 00:16:00,780
بخوانیم، اینجا
305
00:16:00,780 –> 00:16:02,850
NBA را بخوانیم و یک برگه را فشار دهیم که به
306
00:16:02,850 –> 00:16:05,760
طور خودکار آن را پین می کند و اکنون
307
00:16:05,760 –> 00:16:08,490
قاب داده ما قاب داده است. اگر فقط
308
00:16:08,490 –> 00:16:11,250
قاب داده D را اینجا بنویسیم، آیا
309
00:16:11,250 –> 00:16:14,370
سعی می کند ابتدا 30 ستون را چاپ کند و در نهایت 30 ستون
310
00:16:14,370 –> 00:16:17,970
آخر را یک 30 روچ چاپ کند، ببخشید اول
311
00:16:17,970 –> 00:16:20,880
30 سطر و سپس 30 سطر آخر و
312
00:16:20,880 –> 00:16:22,590
سپس شما اینجا را در نقطه نقطه می بینید
313
00:16:22,590 –> 00:16:27,090
که به این معنی است که اینها در بین این دو
314
00:16:27,090 –> 00:16:30,920
ردیف همه روژ دیگر رد شده است
315
00:16:30,920 –> 00:16:37,080
و می توانید او را ببینید و دارای 1 2 3 4 5 6
316
00:16:37,080 –> 00:16:43,380
7 8 و ستونهای 9 x 9 خوب است حالا
317
00:16:43,380 –> 00:16:48,810
ببینیم آیا میخواهیم فقط پیو را چاپ
318
00:16:48,810 –> 00:16:51,090
319
00:16:51,090 –> 00:16:51,600
320
00:16:51,600 –> 00:16:55,320
کنیم.
321
00:16:55,320 –> 00:16:59,850
و اگر a را فشار دهید اگر
322
00:16:59,850 –> 00:17:04,459
نشانگر خود را بین این
323
00:17:04,459 –> 00:17:07,709
پرانتز قرار دهید و اگر ذخیره کنید اگر shift را فشار دهید
324
00:17:07,709 –> 00:17:10,589
و تب را در اینجا خواهید دید
325
00:17:10,589 –> 00:17:14,520
به طور پیش فرض n برابر است با 5 سمت راست
326
00:17:14,520 –> 00:17:18,240
و اگر shift و double tab را فشار دهید
327
00:17:18,240 –> 00:17:20,099
به طور خودکار انجام می شود.
328
00:17:20,099 –> 00:17:23,520
اسناد پیش رو را گسترش دهید و می توانید
329
00:17:23,520 –> 00:17:25,770
در اینجا به زیر بروید و می توانید آن
330
00:17:25,770 –> 00:17:29,340
را با کمی جزئیات بیشتر درک کنید، بنابراین
331
00:17:29,340 –> 00:17:31,650
اگر اینجا 1 تایپ کنید فقط یک ردیف چاپ می شود
332
00:17:31,650 –> 00:17:35,130
اگر اینجا تایپ کنید 0 اگر اینجا تایپ کنید
333
00:17:35,130 –> 00:17:38,340
هیچ ردیفی چاپ نمی شود. 10
334
00:17:38,340 –> 00:17:42,870
اکنون 10 ردیف اول را در اینجا چاپ می کند، ممکن
335
00:17:42,870 –> 00:17:46,230
است تعجب کنید که
336
00:17:46,230 –> 00:17:49,140
اگر می خواهید آخرین بار ردیف را چاپ کنید، چه تکنیکی
337
00:17:49,140 –> 00:17:51,690
دارد، می توانید با روش دم چاپ کنید که به
338
00:17:51,690 –> 00:17:55,590
طور پیش فرض Wendy F dot tail است
339
00:17:55,590 –> 00:17:59,010
DF نه آنها پنج تا را می گیرند.
340
00:17:59,010 –> 00:18:02,090
به این معنی است که ابتدا آخرین ردیف های لوله را چاپ می کند
341
00:18:02,090 –> 00:18:06,780
و اگر اینجا تایپ کنید یک دهم en
342
00:18:06,780 –> 00:18:10,080
آخرین ردیف را چاپ میکند و اگر اینجا صفر تایپ کنید، اگر اینجا هم تایپ کنید
343
00:18:10,080 –> 00:18:13,800
هیچ ردیفی چاپ نمیکند،
344
00:18:13,800 –> 00:18:16,500
سپس
345
00:18:16,500 –> 00:18:22,590
دو سطر آخر موجود در قاب داده شما را در حال
346
00:18:22,590 –> 00:18:28,290
حاضر چاپ میکند یک چیز دیگر، مثلاً اگر
347
00:18:28,290 –> 00:18:30,450
این نوع قاب داده و شما
348
00:18:30,450 –> 00:18:33,750
می خواهید این نام را به عنوان یک شاخص درست
349
00:18:33,750 –> 00:18:36,390
کنید، بنابراین در اینجا می بینید که ایندکس به طور پیش فرض دو
350
00:18:36,390 –> 00:18:38,880
صفر یک دو سه چهار نوع است،
351
00:18:38,880 –> 00:18:40,740
فرض کنید اگر می خواهید یک نمایه با این
352
00:18:40,740 –> 00:18:44,130
نام ایجاد کنید، پس چگونه می توانید هر کدام را انجام دهید، می توانید
353
00:18:44,130 –> 00:18:46,679
تنظیم کنید. یک ایندکس یا میتوانید
354
00:18:46,679 –> 00:18:49,200
قاب دادهتان را بهطور پیشفرض بخوانید، زیرا من این نام را ایندکس میکنم،
355
00:18:49,200 –> 00:18:52,170
بنابراین چگونه میتوانیم این کار را انجام دهیم که میتوانیم
356
00:18:52,170 –> 00:18:59,250
مانند TF بنویسیم، سپس نرخ نقطهای PD را در CSV
357
00:18:59,250 –> 00:19:03,780
بنویسیم و سپس میتوانیم CSV نقطه B را وارد کنیم و اگر
358
00:19:03,780 –> 00:19:07,470
اینجا را فشار دهیم Shift + را فشار دهیم.
359
00:19:07,470 –> 00:19:10,050
در اینجا خواهید دید که پیشنهادات زیادی وجود دارد،
360
00:19:10,050 –> 00:19:13,559
خوب است، بنابراین در اینجا ما ستون نمایه داریم،
361
00:19:13,559 –> 00:19:17,750
باید اینجا بنویسیم ستون فهرست خوب
362
00:19:17,750 –> 00:19:21,510
ستون فهرست، بنابراین ستون فهرست، ما یک
363
00:19:21,510 –> 00:19:25,140
نام داریم، خوب است، بنابراین اگر نام خود را تایپ کردید و
364
00:19:25,140 –> 00:19:29,580
بیایید رویداد را اینجا ببریم. اکنون می بینید که
365
00:19:29,580 –> 00:19:32,550
در اینجا ستون ایندکس به این نام تبدیل شده است
366
00:19:32,550 –> 00:19:36,200
که می توانیم ایندکس را انجام دهیم lumn از هر
367
00:19:36,200 –> 00:19:40,080
چیزی مانند موقعیت شماره تیم و غیره
368
00:19:40,080 –> 00:19:44,040
هر چیزی که دوست دارید خوب است، بنابراین این
369
00:19:44,040 –> 00:19:51,120
راهی است که چگونه میتوانیم ایندکس را خوب تنظیم کنیم.
370
00:19:51,120 –> 00:19:57,810
371
00:19:57,810 –> 00:20:01,440
372
00:20:01,440 –> 00:20:02,460
373
00:20:02,460 –> 00:20:05,160
374
00:20:05,160 –> 00:20:09,750
عملیات فریم مانند بافتن دادهها را
375
00:20:09,750 –> 00:20:11,880
تجزیه و تحلیل میکند و همه آن چیزها را میپذیرد،
376
00:20:11,880 –> 00:20:16,080
بنابراین برای آن چیزهایی که قرار
377
00:20:16,080 –> 00:20:21,500
است با مجموعه دادههای فیلم IMDB
378
00:20:21,500 –> 00:20:26,370
انجام دهم، بیایید آن فریم داده فیلم را بارگذاری کنیم که
379
00:20:26,370 –> 00:20:28,650
میتوانیم با df’ انجام دهیم و سپس البته
380
00:20:28,650 –> 00:20:35,760
BD نه CSV را بخوانید و سپس ما اینجا
381
00:20:35,760 –> 00:20:42,660
هستم I am من مجموعه داده های فیلم تلویزیونی هستم و
382
00:20:42,660 –> 00:20:47,940
سپس ستون زیرخط ایندکس برابر است با
383
00:20:47,940 –> 00:20:50,940
اوکی است، بعداً به شما نشان خواهم داد که چگونه می توانیم
384
00:20:50,940 –> 00:20:55,110
این کار را انجام دهیم وقتی این را بارگذاری کردید و اگر
385
00:20:55,110 –> 00:20:59,310
نقطه F را در اینجا چاپ کنید سر شما اینجا را خواهید دید
386
00:20:59,310 –> 00:21:04,920
اینها لوله ها هستند اینجا را ببینید
387
00:21:04,920 –> 00:21:08,190
لوله Rouge چاپ شده است، بنابراین فرض کنید
388
00:21:08,190 –> 00:21:11,310
اگر من می خواهم فهرست خود را تنظیم کنم، عنوان
389
00:21:11,310 –> 00:21:16,590
رتبه ما خوب است، بنابراین آنچه که ما می توانیم انجام دهیم،
390
00:21:16,590 –> 00:21:20,210
می توانیم اینجا بنویسیم فراخوانی فهرست برابر با
391
00:21:20,210 –> 00:21:21,920
عنوان است،
392
00:21:21,920 –> 00:21:27,150
خوب حالا عنوان به یک فراخوان شاخص تبدیل شده است
393
00:21:27,150 –> 00:21:32,250
یا می توانیم اینجا بنشینیم nk باشه ببینید
394
00:21:32,250 –> 00:21:35,340
اینجا رتبه الان هست ستون ایندکس هستن
395
00:21:35,340 –> 00:21:39,720
و بقیه ستون غیر شاخص هستند
396
00:21:39,720 –> 00:21:45,270
خوب حالا فرض کنید اگر
397
00:21:45,270 –> 00:21:49,920
میخواید لوله آخر ده سطر از
398
00:21:49,920 –> 00:21:52,380
قاب داده شما هستش البته
399
00:21:52,380 –> 00:21:57,410
تا اون موقع می تونید استفاده کنید پنج ردیف آخر رو چاپ میکنه حالا
400
00:21:57,410 –> 00:22:05,100
996 تا 1000 رول عالی است جدا از این
401
00:22:05,100 –> 00:22:08,820
، فرض کنید
402
00:22:08,820 –> 00:22:13,380
اگر میخواهید کمی بیشتر کار کنید، اگر اطلاعات بیشتری
403
00:22:13,380 –> 00:22:15,420
در مورد چارچوب داده میخواهید، چگونه
404
00:22:15,420 –> 00:22:16,560
میتوانید انجام دهید
405
00:22:16,560 –> 00:22:21,060
، اگر اطلاعات درست فکر میکنید، D را انجام دهید تا اطلاعات را
406
00:22:21,060 –> 00:22:25,100
چاپ کند. در مورد دادههای
407
00:22:25,100 –> 00:22:28,560
شما، مانند آنچه در اینجا میبینید، دو
408
00:22:28,560 –> 00:22:31,560
جزئیات اساسی در مورد مجموعه دادههای شما ارائه میکند،
409
00:22:31,560 –> 00:22:34,170
مانند تعداد ردیفها و
410
00:22:34,170 –> 00:22:38,340
ستونها، تعداد مقادیر غیر تهی،
411
00:22:38,340 –> 00:22:40,980
نوع دادهها در هر ستون
412
00:22:40,980 –> 00:22:43,650
و چه مقدار حافظه در قاب دادههای شما
413
00:22:43,650 –> 00:22:47,700
استفاده میکند. اینجا را می بینید که این یک شی غیر پوچ
414
00:22:47,700 –> 00:22:48,480
است،
415
00:22:48,480 –> 00:22:52,620
این شی شیء شی است و
416
00:22:52,620 –> 00:22:56,720
گوش int 64 نوع زمان اجرا اینجا است دقیقه
417
00:22:56,720 –> 00:23:00,870
64 این شناور 64 است و این در
418
00:23:00,870 –> 00:23:06,270
64 است و این یک شناور 64 است سمت راست و
419
00:23:06,270 –> 00:23:09,660
قاب داده اینچ بیشتر است. از 93 کیوی
420
00:23:09,660 –> 00:23:12,330
یعنی تاکی است در حال حاضر یک حافظه حدود 94
421
00:23:12,330 –> 00:23:16,650
کیلوبایت در رایانه من وجود دارد،
422
00:23:16,650 –> 00:23:19,020
فرض کنید اگر می خواهید
423
00:23:19,020 –> 00:23:21,390
شکل قاب داده خود را بفهمید، باید بنویسید DF
424
00:23:21,390 –> 00:23:24,180
امن نیست، یعنی نشان می دهد
425
00:23:24,180 –> 00:23:27,150
که 1000 ردیف در قاب داده شما
426
00:23:27,150 –> 00:23:31,490
و 11 ستون در قاب داده شما وجود دارد. قاب داده
427
00:23:31,490 –> 00:23:38,070
جدا از این که کاربرد این
428
00:23:38,070 –> 00:23:41,070
شکل درست چیست، بنابراین
429
00:23:41,070 –> 00:23:43,650
زمانی که ما
430
00:23:43,650 –> 00:23:45,780
با تمیز کردن و
431
00:23:45,780 –> 00:23:48,750
تبدیل داده ها با این ذخیره کار می
432
00:23:48,750 –> 00:23:51,240
کنیم، از این شکل زیاد استفاده خواهید کرد و می توانیم بفهمیم که چند ردیف است. ستون
433
00:23:51,240 –> 00:23:53,940
به دلیل دوبله بودن حذف شده است،
434
00:23:53,940 –> 00:23:55,740
خوب
435
00:23:55,740 –> 00:23:59,070
حالا بیایید سعی کنیم یک تکراری را مدیریت کنیم که چگونه
436
00:23:59,070 –> 00:24:03,630
می توانیم این تکراری را مدیریت کنیم،
437
00:24:03,630 –> 00:24:10,140
کاری که در اینجا انجام می دهیم، ابتدا می خواهیم
438
00:24:10,140 –> 00:24:13,530
ببینیم آیا تکراری وجود دارد یا خیر، بنابراین چگونه
439
00:24:13,530 –> 00:24:18,500
می توانیم این کار را انجام دهیم. فقط D F نقطه
440
00:24:18,500 –> 00:24:22,800
تکراری خوب است، بنابراین اگر اینجا را ببینیم،
441
00:24:22,800 –> 00:24:26,490
می گوید که اگر
442
00:24:26,490 –> 00:24:29,630
در هر ردیفی تکراری وجود داشته باشد، می گوید که وجود دارد
443
00:24:29,630 –> 00:24:34,160
که یک تکراری دارد، اوکی است و اگر اینجا بگوییم
444
00:24:34,160 –> 00:24:38,120
مقداری DF تکرار نشده است،
445
00:24:38,120 –> 00:24:40,970
اگر وجود داشته باشد چاپ می شود. تکراری که
446
00:24:40,970 –> 00:24:44,780
w است در صورتی که صفر تکراری وجود دارد خوب حالا
447
00:24:44,780 –> 00:24:48,590
فرض کنید اگر یک DF داریم که در آن
448
00:24:48,590 –> 00:24:56,270
DF نقطه را اضافه می کنیم خوب اگر درست است و
449
00:24:56,270 –> 00:25:00,590
سپس یک شکل DF 1 نقطه ای داریم که اینجا را می بینید
450
00:25:00,590 –> 00:25:03,950
اکنون دو هزار ردیف قبل از آن
451
00:25:03,950 –> 00:25:07,280
داریم فقط یک هزار ردیف داشتیم. این بدان معناست
452
00:25:07,280 –> 00:25:09,320
که کاری که انجام دادهایم،
453
00:25:09,320 –> 00:25:14,750
قاب دادهای DF 1 DF را روی یک DF دیگر انباشتهایم، زمانی
454
00:25:14,750 –> 00:25:18,230
که 1000 ردیف تکراری وجود دارد، اکنون چگونه
455
00:25:18,230 –> 00:25:21,080
میتوانیم بفهمیم که چند ردیف تکراری
456
00:25:21,080 –> 00:25:27,490
با همان روشها برخی از DF درست تکرار نشدهاند،
457
00:25:27,730 –> 00:25:33,169
بنابراین میگوید که
458
00:25:33,169 –> 00:25:40,880
هیچ تکراری وجود ندارد. در حال حاضر بیایید ببینیم
459
00:25:40,880 –> 00:25:44,809
چند ستون تکراری در
460
00:25:44,809 –> 00:25:51,429
یک DF 1 وجود دارد، بنابراین چگونه می توانیم اینجا DF 1 را انجام دهیم.
461
00:25:51,429 –> 00:25:54,740
تکثیر شده و سپس
462
00:25:54,740 –> 00:25:57,950
یک مجموع اعمال می کنیم و می گوید
463
00:25:57,950 –> 00:26:02,270
1000 ببخشید وجود دارد 1000 ردیف به
464
00:26:02,270 –> 00:26:04,909
یک DF 1 کپی می شود که البته می دانیم
465
00:26:04,909 –> 00:26:07,700
که 1000 ردیف است که تکرار شده است
466
00:26:07,700 –> 00:26:11,210
چرا 1000 ردیف چون من
467
00:26:11,210 –> 00:26:15,679
DF را با دیگری اضافه کرده بودم. DF
468
00:26:15,679 –> 00:26:19,039
زمانی است که یک DF وجود دارد و سپس من
469
00:26:19,039 –> 00:26:24,140
و همان DF را به DF 1 اضافه کرده بودم، پس چگونه
470
00:26:24,140 –> 00:26:27,559
می توانیم این را حذف کنیم، فرض کنید که می
471
00:26:27,559 –> 00:26:31,100
خواهیم یک قاب داده جدید را در DF 2 ذخیره کنیم، سپس
472
00:26:31,100 –> 00:26:34,580
چگونه می توانیم انجام دهیم، می توانیم اینجا بنویسیم df1 که
473
00:26:34,580 –> 00:26:37,880
drop اگر در اینجا تایپ کنیم drop کنید و یک زبانه را فشار دهید،
474
00:26:37,880 –> 00:26:42,920
به شما پیشنهاد میکند که تکراری
475
00:26:42,920 –> 00:26:47,540
را رها کنید و دشمنان را که تعداد آنها نیست را رها کنید و
476
00:26:47,540 –> 00:26:50,210
موارد تکراری را رها کنید، بنابراین در اینجا خواهید دید که به
477
00:26:50,210 –> 00:26:53,440
طور خودکار همه موارد تکراری را رها میکند
478
00:26:53,440 –> 00:26:59,420
و حالا اگر اینجا شکل نقطه df2 را ببینیم،
479
00:26:59,420 –> 00:27:04,070
شما دوباره آن را هزار به یازده دریافت خواهد کرد،
480
00:27:04,070 –> 00:27:06,200
اما در همان
481
00:27:06,200 –> 00:27:13,550
زمان اگر بگوییم اینجا d f1 dot sep،
482
00:27:13,550 –> 00:27:22,240
دو هزار به یازده را درست 2011 خواهیم دید،
483
00:27:22,240 –> 00:27:25,250
درست خیلی چیزهای دیگر وجود دارد که
484
00:27:25,250 –> 00:27:27,140
می توانیم با موارد تکراری انجام دهیم.
485
00:27:27,140 –> 00:27:29,720
مکان نما در داخل آن
486
00:27:29,720 –> 00:27:32,650
پاره ntheses و اگر Shift + tab را فشار دهید
487
00:27:32,650 –> 00:27:36,890
، در اینجا
488
00:27:36,890 –> 00:27:42,400
اسناد تکراری را می بینید که می گوید حفظ ok وجود
489
00:27:42,400 –> 00:27:48,770
دارد و این اولین چیزی است
490
00:27:48,770 –> 00:27:51,080
که به این معنی است که فقط اولین تکراری را نگه می دارد
491
00:27:51,080 –> 00:27:52,940
و سایر موارد تکراری را حذف می کند
492
00:27:52,940 –> 00:27:55,700
و سپس وجود دارد. در جایی
493
00:27:55,700 –> 00:27:58,760
که اشتباه شما خوب است در جای خود یعنی
494
00:27:58,760 –> 00:28:06,020
بیایید بگوییم اگر اینجا بگویم d f1 dot drop
495
00:28:06,020 –> 00:28:10,640
duplicates خوب است که تکراری را حذف کرده است
496
00:28:10,640 –> 00:28:12,380
اگر اینجا را بررسی کنیم
497
00:28:12,380 –> 00:28:15,560
ACEF اینجا را می بینید که تکراری را حذف کرده است
498
00:28:15,560 –> 00:28:18,830
اما اگر دوباره اینجا را بررسی کنم
499
00:28:18,830 –> 00:28:19,820
F
500
00:28:19,820 –> 00:28:23,300
آن را حفظ کنید. می گوید که میلی متر اوکی است زیرا در
501
00:28:23,300 –> 00:28:27,200
محل درست نیست اگر بگویم اینجا در
502
00:28:27,200 –> 00:28:36,050
جای درست است، پس اگر آن را اجرا کنم خوب است فقط
503
00:28:36,050 –> 00:28:39,830
اگر این را اجرا کنم اینجا را ببینید
504
00:28:39,830 –> 00:28:43,430
اکنون DF یکی 1000 است
505
00:28:43,430 –> 00:28:46,970
، یعنی نسخه تکراری را رها کرده و دارد
506
00:28:46,970 –> 00:28:51,110
یک قاب داده جدید را در D F 1 قرار داد که در آن زمان
507
00:28:51,110 –> 00:28:55,580
DF 1 تغییر کرده است
508
00:28:55,580 –> 00:28:59,490
بسیار خوب حالا بیایید بفهمیم چگونه می
509
00:28:59,490 –> 00:29:02,040
توانیم یک ستون را پاکسازی کنیم، حالا اجازه دهید
510
00:29:02,040 –> 00:29:06,150
چند سلول دیگر را در اینجا اضافه کنیم تا کار با آن راحت باشد،
511
00:29:06,150 –> 00:29:11,120
حالا بیایید با
512
00:29:11,840 –> 00:29:19,530
ستون های پاک کار کنیم. باشه تو اینجا را ببینید بیایید
513
00:29:19,530 –> 00:29:23,130
اینجا ببینیم چگونه میتوانیم یک ستون را
514
00:29:23,130 –> 00:29:26,880
فقط به ستونهای D F نقطه چاپ کنیم، حالا میبینید
515
00:29:26,880 –> 00:29:29,430
که اینجا ستون اینجا داریم اینها
516
00:29:29,430 –> 00:29:32,160
ستونها هستند و اگر بخواهیم در اینجا چاپ کنیم
517
00:29:32,160 –> 00:29:34,890
طول چند ستون وجود دارد
518
00:29:34,890 –> 00:29:40,400
، 11 میگیرید، بنابراین
519
00:29:40,400 –> 00:29:44,280
اگر
520
00:29:44,280 –> 00:29:46,650
میخواهید اطلاعات بیشتری در مورد این برگ به دست آورید، اگر میخواهید اطلاعات بیشتری در مورد این نوع برگ به دست آورید، ستونهای
521
00:29:46,650 –> 00:29:49,680
F نقطهای را در اینجا خواهید دید، اگر توضیح داده نشده باشد،
522
00:29:49,680 –> 00:29:52,410
نوع دیگری از
523
00:29:52,410 –> 00:29:57,840
تجزیه و تحلیل آماری یک DF را دریافت خواهید
524
00:29:57,840 –> 00:30:02,400
525
00:30:02,400 –> 00:30:06,990
کرد. آن لیست فراخوانی می شود و اگر
526
00:30:06,990 –> 00:30:10,500
در اینجا چاپ کنیم، این لیست را فراخوانی کنید، خوب است
527
00:30:10,500 –> 00:30:16,260
و اگر در اینجا ببینیم که نوع این
528
00:30:16,260 –> 00:30:20,160
لیست است، خوب است، یا می توانیم آن را
529
00:30:20,160 –> 00:30:22,860
به یک لیست در اینجا تبدیل کنیم، اگر اینجا را دیدیم
530
00:30:22,860 –> 00:30:30,870
تایپ کنید okay ببینید اینجا این است
531
00:30:30,870 –> 00:30:34,380
لیست بسیار خوب است، بنابراین در اینجا ما یک تماس داریم
532
00:30:34,380 –> 00:30:36,660
که عنوان شرح کلی کارگردان
533
00:30:36,660 –> 00:30:40,260
بازیگر در زمان اجرا رتبه بندی کلمات درآمد
534
00:30:40,260 –> 00:30:46,200
و نمره متوسط در حال حاضر کاری که می خوا
535
00:30:46,200 –> 00:30:50,460
م اینجا انجام دهم، نام این ست
536
00:30:50,460 –> 00:30:54,450
ن ها را تغییر می دهم، خوب چگونه می توانیم نام این ست
537
00:30:54,450 –> 00:30:56,850
ن ها را در آنجا تغییر دهیم. دو چیز هستند
538
00:30:56,850 –> 00:30:59,820
آنها دو راه هستند یا می توانم اینجا ارائه
539
00:30:59,820 –> 00:31:01,950
دهم، فرض کنید این تماس است و اینجا
540
00:31:01,950 –> 00:31:06,630
این یک تماس است، خوب است یا می توانم
541
00:31:06,630 –> 00:31:09,180
عرض ستون را به تازگی تنظیم کنم
542
00:31:09,180 –> 00:31:12,090
یا می توانیم نام ستون را تغییر دهیم، بنابراین در اینجا می
543
00:31:12,090 –> 00:31:15,000
خواهم ستون را با لیست جدید تنظیم کنم.
544
00:31:15,000 –> 00:31:17,700
بسیار خوب، بنابراین لیست جدید فقط یک لیست بسیار
545
00:31:17,700 –> 00:31:23,010
تصادفی در اینجا است، پس ما یک B
546
00:31:23,010 –> 00:31:29,150
داریم، سپس یک مشاهده در اینجا داریم، سپس یک d e
547
00:31:29,150 –> 00:31:36,090
و سپس f، زمانی که یک G داریم، در نهایت
548
00:31:36,090 –> 00:31:39,510
کل اینجا 11 ستون است، بنابراین ما به 11 ستون نیاز داریم
549
00:31:39,510 –> 00:31:45,090
1 2 3 4 5 6 7 8 درست است و اکنون ما
550
00:31:45,090 –> 00:31:55,200
به چند H I J دیگر نیاز داریم و در اینجا ما یک
551
00:31:55,200 –> 00:31:58,740
کلید داریم، بنابراین آنچه را که قرار است
552
00:31:58,740 –> 00:32:01,140
انجام دهیم، اینجا را تایپ کنید،
553
00:32:01,140 –> 00:32:06,870
پس از ستون هایی که برابر است با 1 تماس بگیرید، حالا
554
00:32:06,870 –> 00:32:13,380
بیایید این DF را اینجا ببینید. حالا
555
00:32:13,380 –> 00:32:17,670
ستون جدید بعد از D اگر همین الان است،
556
00:32:17,670 –> 00:32:21,